
1. 빅데이터의 주요 처리 과정
- 수집, 저장, 처리, 분석
- 빅데이터는 기존의 데이터와 속성이 다르기 때문에, 수집, 저장, 처리, 분석을 위해 새로운 기술이 필요
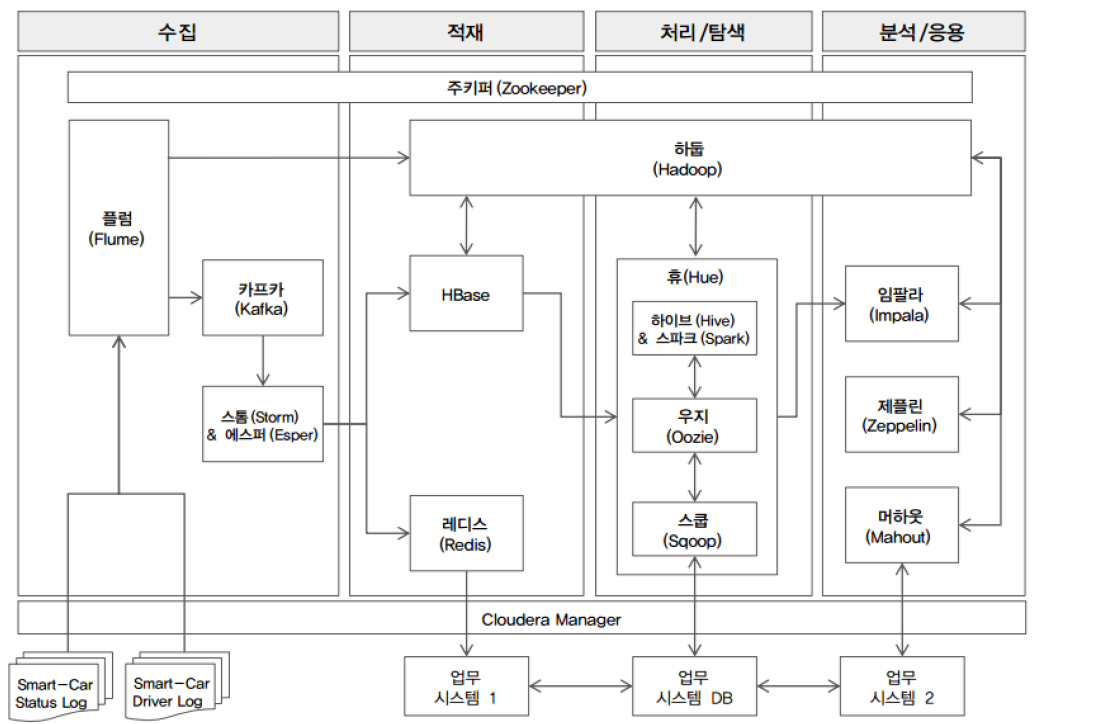
2. 데이터 수집
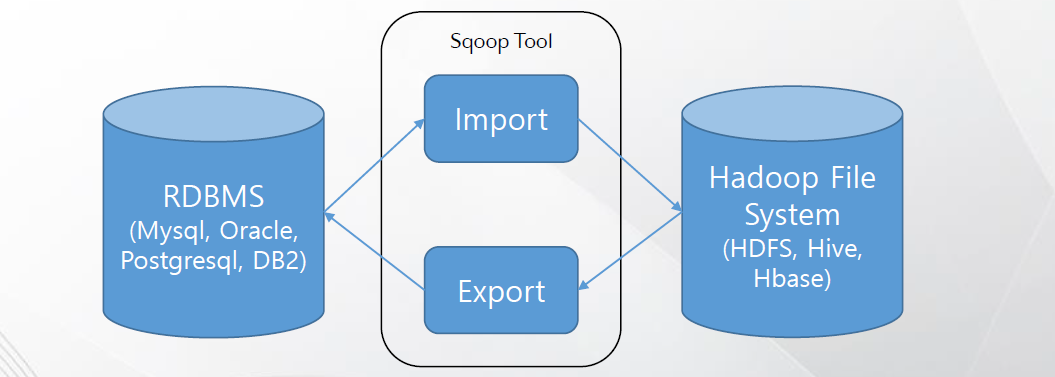
1) SQOOP
- 정형 데이터의 자동 수집을 위해 사용되는 대표적인 오픈소스 기반 도구
- 관계형 데이터베이스와 하둡 간에 데이터를 전송할 수 있도록 설계된 도구
- 관계형 데이터 베이스(RDBMS)와 하둡과 같은 빅데이터 저장 플랫폼(HDFS) 간의 임포트/익스포트 제공
- 관계형 데이터베이스에 접근하기 위해 JDBC 또는 ODBC 방식 사용
- 맵리듀스를 기반으로 구현된 데이터 적재 프로그램(맵리듀스는 정렬되지 않은 데이터들을 속성이 같은 데이터와 묶어 분류해주는 역할)
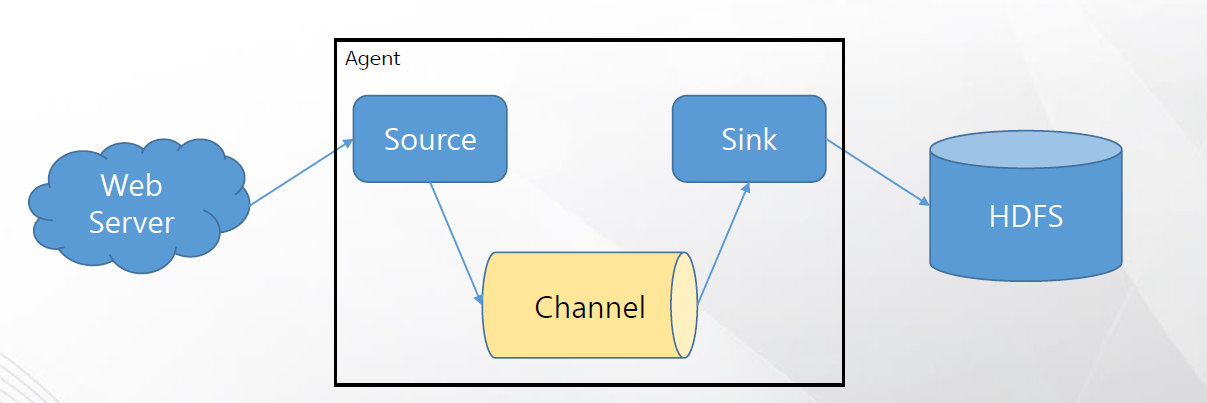
2) Flume
- 시스템 또는 웹 서버의 로그를 수집할 수 있는 기술
- IoT 환경의 센싱 데이터를 수집할 수 있는 기술
- 수집된 데이터를 하둡에 저장
- 장애가 나더라도 로그를 유실 없이 전송할 수 있는 신뢰성 있는 기술
- 고장방지 능력이 Flume의 핵심 설계 원칙
🔔 대규모 분산 시스템은 부분적인 장애가 발생하기 쉬움
- 장비의 물리적 고장
- 네트워크 대역폭, 메모리 등의 자원이 꽉 참
- 소프트웨어가 다운되거나 느리게 실행
3) Crawling
- 인터넷에 있는 데이터를 수집하기 위해 사용하는 기술
4) Open API
- 공공기관 등에서 제공하는 데이터를 수집할 수 있는 기술
3. 데이터 저장
🔔 하둡(Hadoop)
- HDFS와 맵리듀스를 구현한 빅데이터 저장 및 처리 기술의 대표적인 프레임워크
- 여러 개의 저렴한 컴퓨터를 마치 하나인 것처럼 묶어 대용량 데이터 처리
- 수천 대의 분산된 장비에 대용량 파일을 저장할 수 있는 기능을 제공하는 분산파일 시스템과, 저장된 데이터를 분산된 서버의 cpu와 메모리 자원을 이용해 쉽고 빠르게 분석할 수 있는 컴퓨팅 플랫폼인 맵리듀스로 구성
1) HDFS
- 빅테이터를 여러 노드들에 분산 저장하는 파일 시스템
- 디스크 기반으로 데이터를 저장, 관리 해왔으나 최근에는 실시간 서비스에서의 효율성을 높이고자 메모리 기반의 기술로 발전
2) NoSQL(Hbase, Redis, MongoDB)
- 비정형 데이터베이스
- 실시간성, 확장성을 강화한 기술
4. 데이터 처리
1) Map-Reduce
- 구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 제작
- 일반 범용 서버로 구성된 군집화 시스템을 기반으로 한 분산 컴퓨팅 기술
- 정렬되지 않은 데이터들을 속성이 같은 데이터와 묶어 분류해주는 기술
- 병렬 처리를 위한 스케줄링 등의 복잡한 사항들을 고민하지 않도록 쉬운 방법 제공
- Map과 Reduce 두 함수를 이용하여 데이터 처리
2) Hive
- SQL로 하둡 데이터를 분석하려는 엔지니어들의 요구로 개발
- 하이브는 JDBC나 ODBC로 연동된 여러 서드파티 도구를 통해 사용하거나 CLI프로그램을 통해 사용
3) Pig
- 하둡의 복잡한 추출, 변환, 적재 작업을 손쉽게 구현하려는 요구로 개발
- 하이브가 단발적인 애드혹(ad-hoc) 쿼리에 적합하다면, 피그는 다수의 중간 결과물이 필요한 좀더 복잡한 분석 쿼리에 적합
- 대량의 조인 연산이나 중간 테이블이 필요한 경우 하이브 대신 피그 쿼리를 사용하는 것이 낫다
4) Spark
- 스파크는 맵 리듀스와 비교해 데이터 과학에서 자주 등장하는 반복 연산에 더 적합한 기능을 제공하는 분산 인-메모리 데이터 처리 프레임워크
- 스파크는 기본적인 분산처리 기능 뿐 아니라 스파크SQL, MLlib 등 여러 구성 요소 추가해 아파치 프로젝트로 성장
- 기본 데이터 구조는 객체의 분산 시퀀스인 RDD(Resilient Distributed Dataset)로 휘발성 메모리인 RAM에 저장되면서 자동으로 장애를 극복
- 스파크는 RDD 데이터가 누락되었다면 데이터의 일부분에 대한 연산만 재실행해 복원할 수 있다
- 디스크 기반이 아닌 메모리 기반의 처리기술로 기존 Map-Reduce의 처리 속도보다 10 ~ 100배 빠른 처리 기술
- 데이터를 메모리에 캐시로 저장하는 모델을 사용하기 때문에 머신 러닝 알고리즘에서 더 빠른 속도로 사용 가능
- 여러 노드에 분산된 데이터 참조하고 복잡한 병령 프로그래밍으로 자동 변환하며, 스칼라, 자바, 파이썬 , R 지원
- Spark shell을 이용해 간단한 실험, 테스트 가능
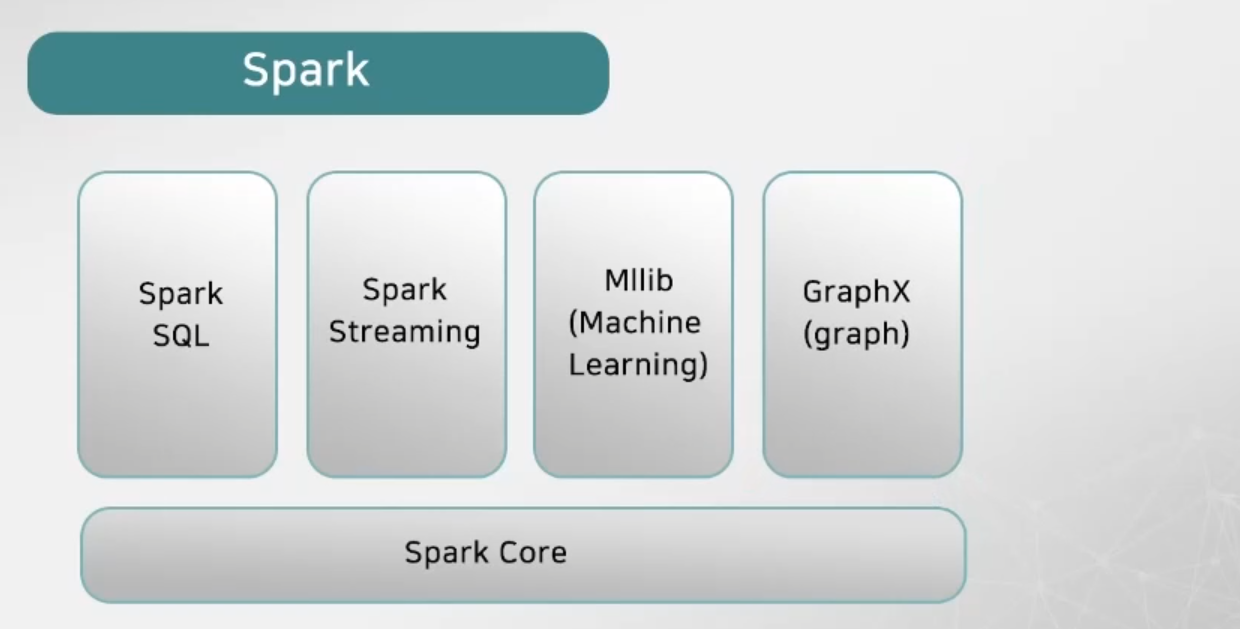
a) Spark Core
- 스파크 컴포넌트에 필요한 기본 기능 제공
- 분산 데이터 컬렉션(데이터셋)을 추상화한 객체인 RDD(Resilent Distributed Dataset)로 다양한 연산 및 변환 메소드 제공
- RDD는 노드에 장애가 발생해도 데이터셋을 재구성 할 수 있는 복원성을 가짐
- 스파크와 하이브 SQL이 지원하는 SQL을 사용해 대규모 분산 정형 데이터를 다룸
- JSON파일, RDB테이블, 하이브 테이블 등 다양한 정형 데이터 읽고 쓰기 가능
b) Spark streaming
- 실시간 스트리밍 데이터를 처리하는 프레임워크
- 다른 스파크 컴포넌트와 함께 사용: 실시간 데이터 처리를 머신러닝 작업, SQL작업, 그래프 연산 등으로 통합
c) Spark ML lib
- 머신러닝 알고리즘 라이브러리
- RDD 또는 DataFrame의 데이터셋을 변환하는 머신러닝 모델 구현
🔔 메모리 기반의 데이터 저장 및 처리 기술
- NoSQL, Spark에서 메모리 기반으로 빅데이터를 저장 및 처리하기 위한 기능을 제공
- 기존의 디스크 기반에서 실시간성에 대한 요구 증가로 메모리 기반의 기술이 개발
- 최근에는 메모리의 장점인 빠른 처리속도와, 디스크의 비휘발성을 모두 가지는 플래시 메모리 기반의 데이터베이스가 발전
5. 데이터 분석
- 분석에 사용하는 기술은 대부분 이미 통계학, 기계 학습, 데이터 마이닝 분야에서 이미 사용
- 알고리즘을 대규모 데이터 처리에 맞게 개선하여 적용
- 연관성 분석, 분류 분석, 군집화, 시계열 분석, 회귀 분석