
Apache 데이터 수집
사물 인터넷(IoT) 시대에 접어들게 되면서 이제는 정말 데이터가 홍수처럼 쏟아져 나오고 있습니다. 모든 전자기기에는 센서가 부착되고, 인터넷에는 전 세계에서 만들어진 새로운 정보들이 매일 올라오고 있습니다. 그리고 이제는 이런 데이터들을 최대한 많이 수집하여, 가공하고 분석함으로써 새로운 가치를 창출하는 시대입니다.
데이터의 종류도 다양합니다. 예를 들면 회사에 누적되어 있는 RDB, 센서에서 받아들이는 실시간 비정형 데이터(음성, 영상 등), 인터넷에 올라오는 각종 텍스트, 이미지, 영상 등이 있습니다. 따라서 이러한 데이터를 얼마나 빠르고 적절하게 수집하는지가 굉장히 중요한 기술이 되었습니다. 그래서 저희는 앞으로 빅데이터 생태계에서 이러한 이슈들에 대해 어떤 기술들이 있는지 배워보게 될 것 입니다.
1. SQOOP(정형 데이터)
2. Flume(배치 단위의 비정형 데이터)
- 시스템 또는 웹 서버의 로그를 수집할 수 있는 기술
- IoT 환경의 센싱 데이터를 수집할 수 있는 기술
- 수집된 데이터를 하둡에 저장
- 장애가 나더라도 로그를 유실 없이 전송할 수 있는 신뢰성 있는 기술
- 고장방지 능력이 Flume의 핵심 설계 원칙
🔔 대규모 분산 시스템은 부분적인 장애가 발생하기 쉬움
- 장비의 물리적 고장
- 네트워크 대역폭, 메모리 등의 자원이 꽉 참
- 소프트웨어가 다운되거나 느리게 실행
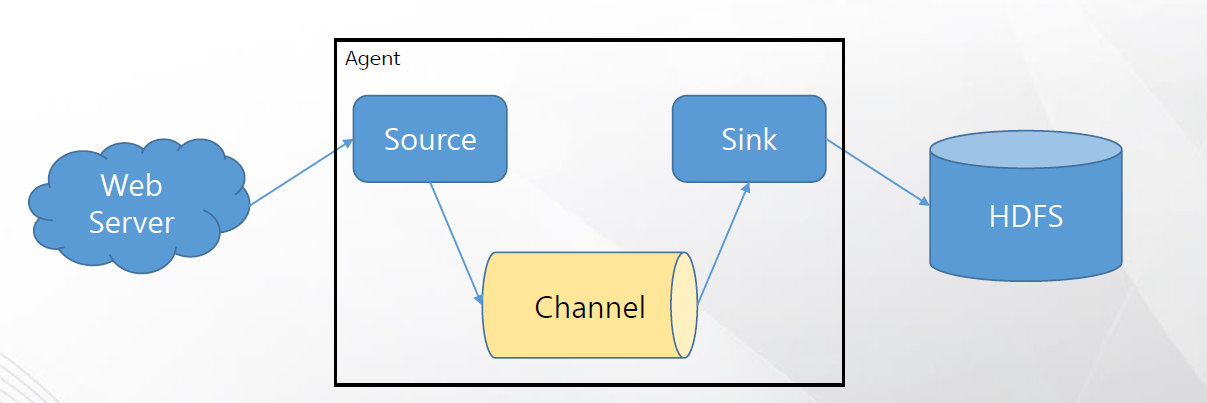
# Apache Flume 공식문서 설명
Flume 이벤트는 바이트 페이로드와 선택적 문자열 속성 집합을 갖는 데이터 흐름의 단위로 정의됩니다.
Flume 에이전트는 이벤트가 외부 소스에서 다음 대상(홉)으로 이동하는 구성 요소를 호스팅하는 JVM(Jume Agent) 프로세스입니다.
Flume Source는 웹 서버와 같은 외부 소스에 의해 제공된 이벤트를 소비합니다.
Flume Source는 이벤트를 수신하면 이벤트를 하나 이상의 Channel에 저장합니다. Channel은 Flume Sink에서 소비될 때까지 이벤트를 유지하는 패시브 스토어입니다.
Sink는 Channel에서 이벤트를 제거하고 HDFS(Flume HDFS 싱크)와 같은 외부 저장소에 넣거나 흐름에서 다음 Flume 에이전트(다음 홉)의 Flume Source로 전달합니다.
3. Kafka(실시간 단위의 비정형 데이터)
- 스트리밍 데이터를 다루기 위한 미들웨어와 그 주변 생태계
- 높은 확장성(scalability)과 가용성(availability)
- 한 번 입력된 데이터는 그 시점에서 영속화(persistency)
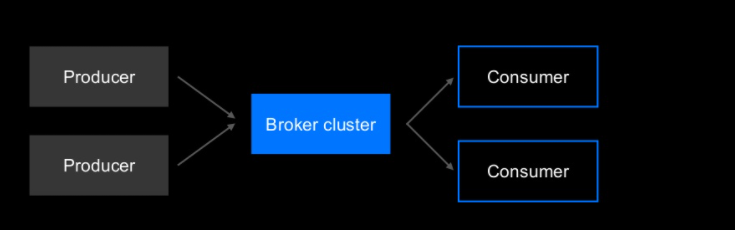
Producer는 Kafka에 데이터를 입력하는 클라이언트
Broker cluster는 임의 개수의 노드로 구성되는 클러스터로 ‘topic’이라고 불리는 데이터 관리 유닛을 임의 개수만큼 호스팅
Consumer는 Kafka에서 데이터를 가져오는 클라이언트
Consumer는 데이터를 가져올 topic을 지정한 후 해당 topic에서 데이터를 가져오는데요.
여기서 중요한 특성은 하나의 topic에 여러 개의 Consumer가 각각 다른 목적으로 존재한다는 점입니다.
일단 topic에 입력된 데이터는 여러 Consumer가 서로 다른 처리를 하기 위해 여러 번 가져올 수 있습니다.
이는 Kafka가 Pub/Sub 모델을 사용한 데이터 분포를 지원하기 때문입니다.