
[부스트캠프 Ai-tech] Pstage 마스크 분류 대회
1. 대회 소개
COVID-19의 확산으로 우리나라는 물론 전 세계 사람들은 경제적, 생산적인 활동에 많은 제약을 가지게 되었습니다. COVID-19가 이렇게 오랜 기간 동안 우리를 괴롭히고 있는 근본적인 이유는 바로 강력한 전염력 때문입니다.
감염자의 입, 호흡기로부터 나오는 비말, 침 등으로 인해 다른 사람에게 쉽게 전파가 될 수 있기 때문에 감염 확산 방지를 위해 무엇보다 중요한 것은 모든 사람이 마스크로 코와 입을 가려서 혹시 모를 감염자로부터의 전파 경로를 원천 차단하는 것입니다.
따라서, 이번 대회에서 우리는 카메라로 비춰진 사람 얼굴 이미지만으로 이 사람의 최소한의 인적 정보와 마스크를 어떻게 쓰고 있는지에 대한 정보를 제공해주는 인공지능 모델을 만들어보려고 합니다.
2. 데이터 분석(EDA)
1) 데이터 개요
본격적으로 모델을 만들기 전에 저는 제공받은 데이터의 품질을 확인해보았습니다. 참고로 제가 제공받은 데이터는 다음과 같습니다.
- 총 인원: 2700명
- 인당 7장의 사진
각 이미지는 다음과 같은 특성을 가지고 있습니다.
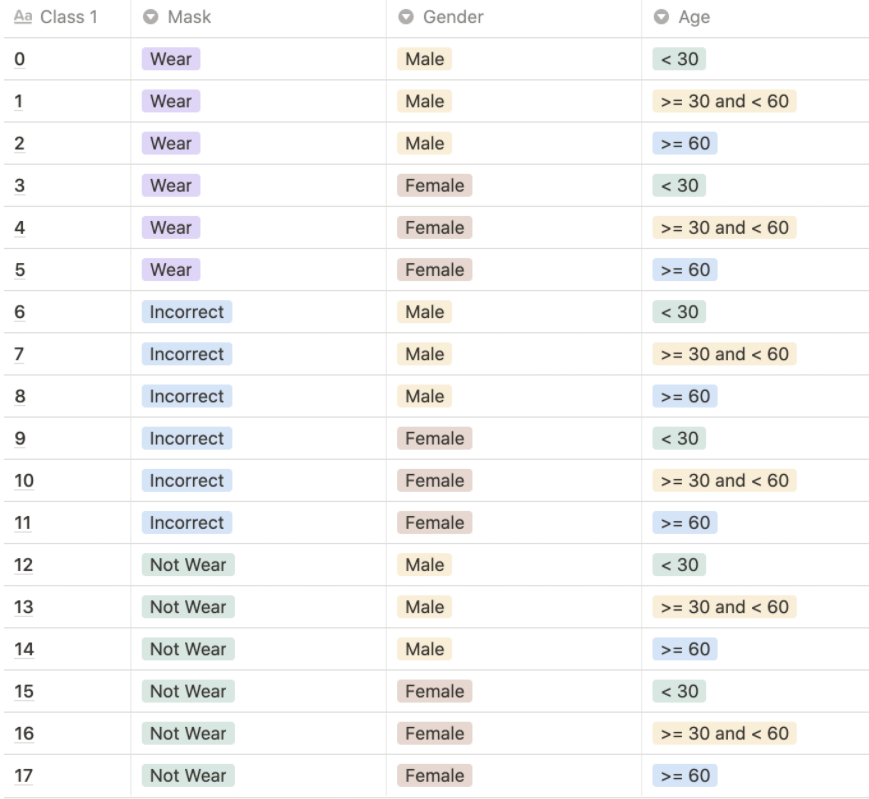
- 남/녀
- 18-29세/30세-59세/60세 이상
- 마스크/부적절한 마스크 착용/미착용
이미지 샘플은 저작권의 문제로 보여드리기가 어렵고, 대략 다음과 같은 모습이라고 생각해주시면 되겠습니다.

2) 데이터 분석
a) 데이터 파일 저장하기
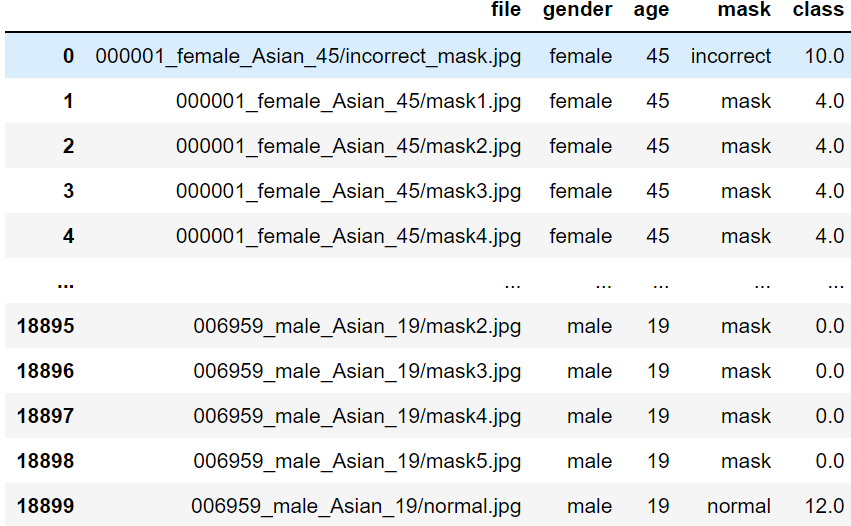
우선 데이터가 사람의 마스크 착용상태별로 폴더로 저장되어 있었습니다.
000123_male_Asian_58
ㄴ mask1.png(마스크 착용 이미지 5장)
ㄴ incorrect.png (부적절한 마스크 착용 이미지 1장)
ㄴ normal.png (마스크 안낀 이미지 1장)
...
002700_female_Asian_45
그래서 우선 폴더명에서 성별과 나이를 추출하고 이미지에서 마스크 착용 여부를 추출하여 레이블링을 해주었습니다.
참고로 레이블링은 다음과 같은 방법으로 해주었습니다.
# 데이터로 부터 특성 추출하여 데이터프레임으로 저장
import os
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame(columns = ['file' , 'gender', 'age', 'mask'])
i = 0
for FOLDER in os.listdir(ROOT_DIR):
for FILE in os.listdir(ROOT_DIR + '/' + FOLDER):
# FOLDER로 부터 성별과 나이 추출
result = re.findall(r'(female|male)|([0-9]+$)', FOLDER)
gender, age = result[0][0], result[1][1]
# FILE로 부터 마스크 여부 추출
result = re.search(r'^(incorrect|mask|normal)', FILE)
mask = result.group(1)
print(FOLDER + FILE, gender, age, mask)
df.loc[i] = [FOLDER+'/'+FILE, gender, int(age), mask]
i += 1
# Labeling
for i in range(len(df)):
if df.loc[i, 'mask'] == 'mask':
if df.loc[i, 'gender'] == 'male':
if df.loc[i, 'age'] < 30:
df.loc[i, 'class'] = 0
elif 30 <= df.loc[i, 'age'] < 60:
df.loc[i, 'class'] = 1
else:
df.loc[i, 'class'] = 2
# mask and female
else:
if df.loc[i, 'age'] < 30:
df.loc[i, 'class'] = 3
elif 30 <= df.loc[i, 'age'] < 60:
df.loc[i, 'class'] = 4
else:
df.loc[i, 'class'] = 5
elif df.loc[i, 'mask'] == 'incorrect':
if df.loc[i, 'gender'] == 'male':
if df.loc[i, 'age'] < 30:
df.loc[i, 'class'] = 6
elif 30 <= df.loc[i, 'age'] < 60:
df.loc[i, 'class'] = 7
else:
df.loc[i, 'class'] = 8
# incorrect and female
else:
if df.loc[i, 'age'] < 30:
df.loc[i, 'class'] = 9
elif 30 <= df.loc[i, 'age'] < 60:
df.loc[i, 'class'] = 10
else:
df.loc[i, 'class'] = 11
# not wear
else:
if df.loc[i, 'gender'] == 'male':
if df.loc[i, 'age'] < 30:
df.loc[i, 'class'] = 12
elif 30 <= df.loc[i, 'age'] < 60:
df.loc[i, 'class'] = 13
else:
df.loc[i, 'class'] = 14
# not wear and female
else:
if df.loc[i, 'age'] < 30:
df.loc[i, 'class'] = 15
elif 30 <= df.loc[i, 'age'] < 60:
df.loc[i, 'class'] = 16
else:
df.loc[i, 'class'] = 17
b) 데이터 카테고리별 분포 확인하기
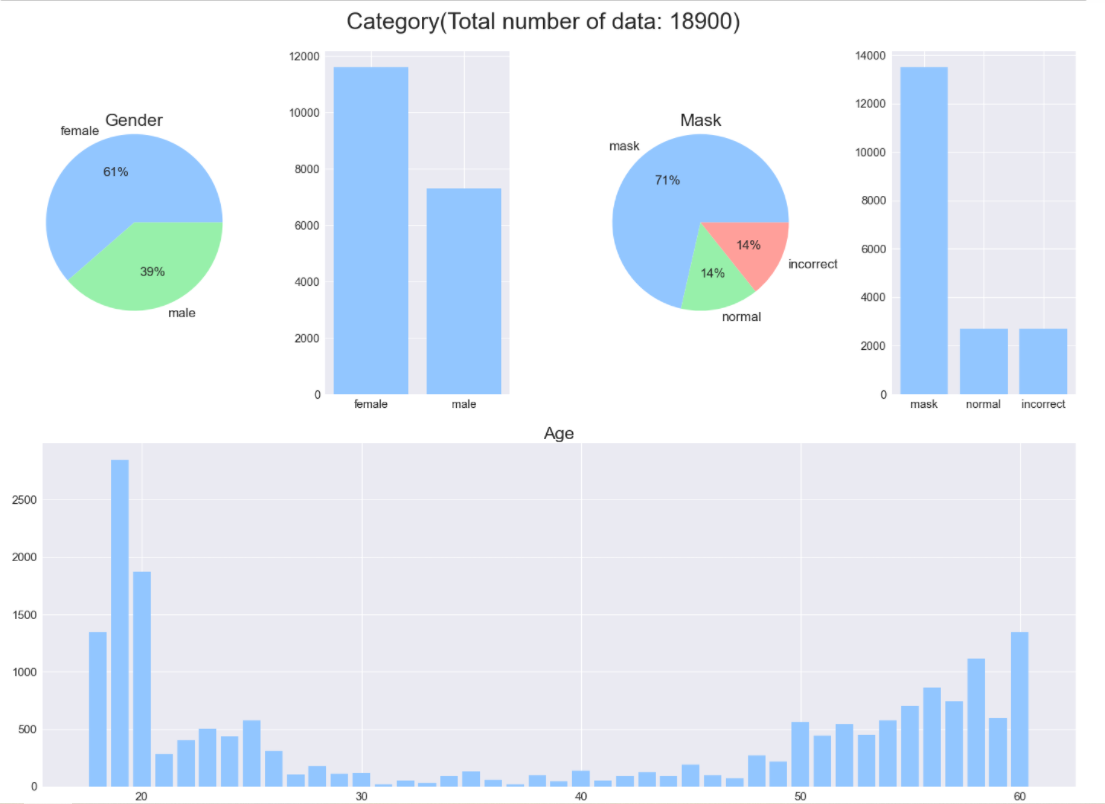
데이터가 성별에서는 여자가 전체 데이터의 약 60%로 조금 더 비중이 크고, 마스크는 압도적으로 착용한 데이터가 많으며, 나이는 20대, 50대 이상의 비중이 압도적으로 많은 분포를 가지고 있습니다.
처음 EDA를 진행할 때에는 특성별로 분포를 확인하고, 남자 데이터를 늘리며 그 중에서도 incorrect와 normal을 늘리고 그 중에서도 20-50대 사이의 데이터를 늘려야겠다. 라고 생각 하였지만 그냥 결론은 결국 class별로 데이터를 늘려주면 되는거였습니다.
그래서 전체 데이터를 카테고리에 따른 분포도 확인해 보았습니다.
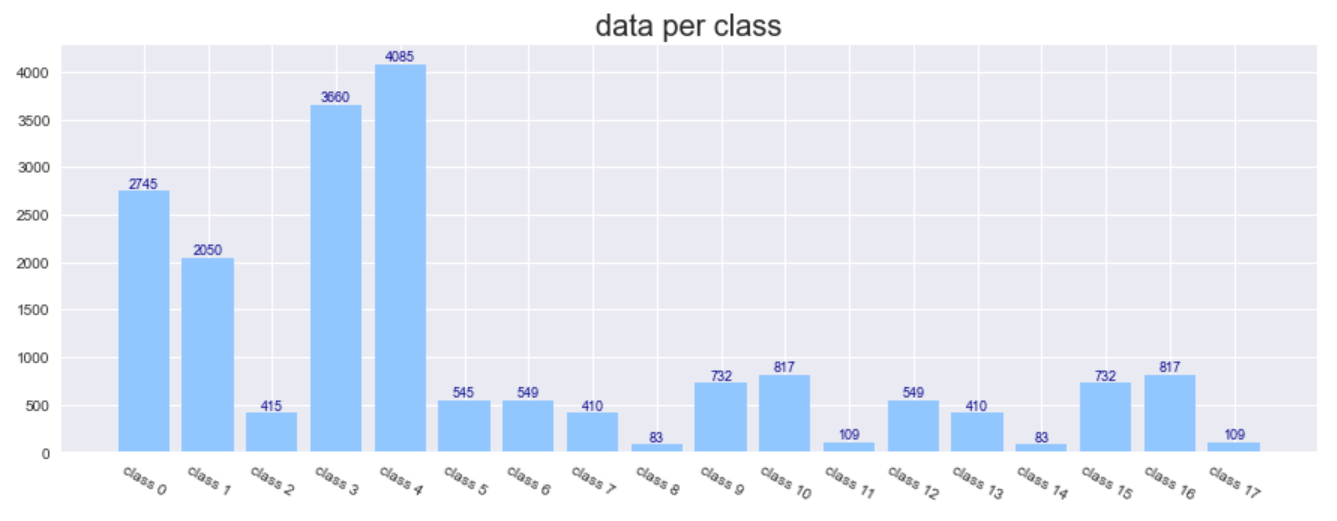
3. 데이터 전처리(Preprocessing)
1) Transform & Augmentation
전처리 과정에서는 우선 Data Augmentation에 가장 초점을 맞추었습니다. 그래서 데이터의 특성을 최대한 살리며 동시에 다양한 특성을 주고자 transform을 진행하여 각 카테고리별로 3000장으로 Oversampling하였습니다. 3000장 이상의 데이터를 이미 가지고 있는 데이터는 Augmentation되지 않도록 하였습니다.
import os
import csv
import random
import pandas as pd
from skimage import io
import random
import torch
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
# root_dir: 이미지 저장 되어있는 폴더
# annotations: 이미지 목록 저장되어 있는 csv
def __init__(self, root_dir, annotations):
self.transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomRotation(degrees=30),
transforms.ColorJitter(brightness=0.5),
transforms.Pad(random.randint(0, 20)),
transforms.Resize((224, 224)),
transforms.ToTensor()
])
self.root_dir = root_dir
self.annotations = pd.read_csv(annotations)
def __len__(self):
return len(self.annotations)
def __getitem__(self, index):
img_path = os.path.join(self.root_dir, self.annotations.loc[index, 'file'])
img = io.imread(img_path)
img = self.transform(img)
label = torch.tensor(int(self.annotations.loc[index, 'class']))
return img, label
class Augmentation:
def __init__(self, root_dir, annotations):
self.dataset = CustomDataset(root_dir, annotations)
def run(self, num):
i = 0
for img, label in DataLoader(self.dataset):
if i + len(self.dataset) > num:
break
i += 1
label = str(int(label.item()))
save_image(img, 'augmented_label'+label+'_folder//'+'image'+str(i)+'_label_'+label+'.png')
with open('augmented_img_class_'+label+'.csv','a') as f:
wr = csv.writer(f)
wr.writerow(['image'+str(i)+'_label_'+label+'.png', label])
for i in [6, 12, 5, 2, 7, 13, 17, 11, 14, 8]:
annotations = ".//mask_class_"+str(i)+".csv"
augmentation = Augmentation(root_dir=".//images//images//", annotations=annotations)
augmentation.run(3000)
이렇게 하면 각 클래스별로 데이터가 최소 3000장 최대 4085장으로 처음과 비교해 균형이 많이 잡아졌습니다.
4. 느낀 점 및 진행 상황
이렇게 데이터 불균형을 어느 정도 잡고 Resnet 모델을 사용하게 되면 성능이 꽤 괜찮을 것이라 기대했습니다. 실제로 train 데이터에서 train/valid로 나누어 학습을 진행했을 때는 기가 막히게 클래스를 잘 예측하였으나, eval에서 본 적 없는 데이터로 테스트 해본 결과 acc는 40%, f1_score는 0.4정도로 결과가 처참하였습니다.

우선 알게된 사실은 Pretrain모델을 사용할 때는 pretrain=True를 하는 것이 좋다는 것이었습니다. 같은 팀에 있는 캠퍼님의 말씀으로는 pretrain=True가 초반에 모델의 가중치가 좋은 출발점을 제공해주기 때문이라고 했습니다. 이 부분은 조금 더 공부를 해보면 좋을 것 같습니다.
앞으로 모델의 구조를 조금 더 개선하여 실험을 진행하고, 결과에 따라 Cutmix 같은 방법으로 추가적인 Augmentation을 실험해볼 계획입니다.