
[부스트캠프 Ai-tech] Pstage 마스크 분류 대회
모델을 어떻게 구성할 것인가
이번 대회를 진행하면서 느끼게 된 것은, 부딪히고 깨지면서 배워야 한다는 것이었습니다. 그동안 데이터를 이용해서 모델 한 번 만들어본 적 없었는데 그 때 까지만 해도 배운 것들을 잘 이해하고 있으면 문제에 직면했을 때 잘 대처할 수 있을거라 생각했는데 전혀 그렇지가 않았습니다.
어디서 문제가 난걸까
처음에는 마스크 착용 문제가 어려운 classification이 아니라 생각해서 Data oversampling만 잘해줘도 pretrained모델로 좋은 성능을 낼 수 있을 것이라 기대했습니다. 그런데 결과가 전혀 기대했던 것과 다르게 나왔습니다. 그 후에 머릿속에 생각이 너무 많아졌습니다.
- 데이터의 문제인가?
- 모델의 문제인가?
- 하이퍼 파라미터의 문제인가?
train/valid에서 prediction값을 보면 0~17의 카테고리를 정말 잘 예측합니다. 정확도 99%를 넘어가는 것을 보고 이 녀석 정말 똑똑하구나 하고 자랑스러워했습니다. 그런데 eval에 갔더니 이 친구가 44444444, 00000000 이런식으로 굉장히 편향된 예측을 하기 시작합니다. epoch가 1일 때는 그나마 조금 나은데 train을 3epoch 이상하게 되면 굉장히 편향되어버립니다.
일단 성능을 단시간에 가장 빨리 올렸던 방법은 eval에서 사용하는 transforms의 Resize 크기를 갖게 맞춘겁니다. 이 방법이 cheating은 아닐까 하여 멘토님께 여쭤보았는데 괜찮다고 말씀하셔서 일단 크기를 맞추고 학습해봤고, 그 결과 편향되던 예측값이 갑자기 굉장히 골고루 분포하게 되었으며 성능도 기존에 비해 30% 이상의 성능 향상을 가져왔습니다.

지금 사용하고 있는 모델의 구조
앞에서 Resnet 하나로 학습을 했을 때는 성능이 안나오자 모델을 다음과 같이 바꿨습니다.
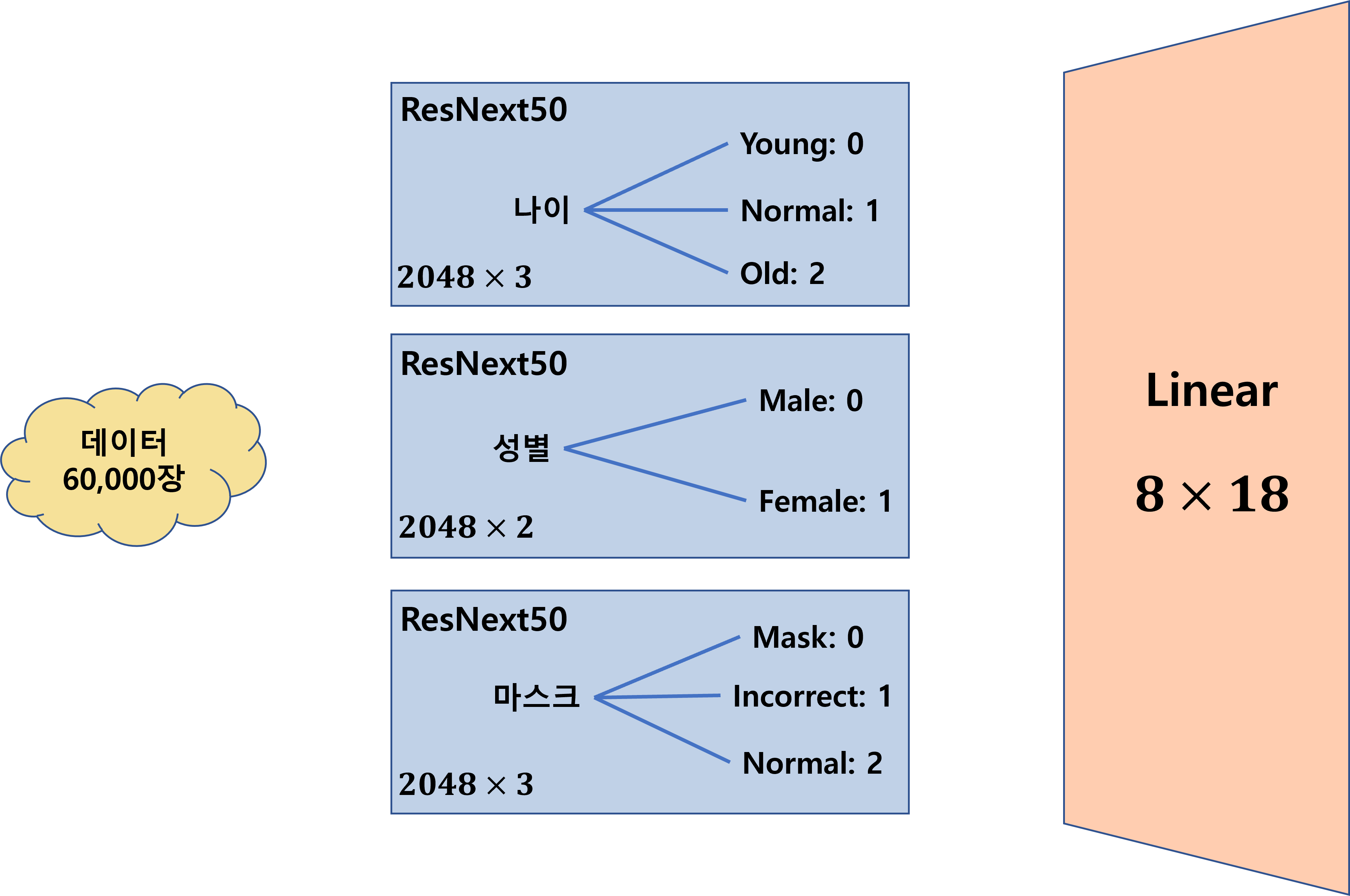
그런데 사실 이렇게 해도 이미지를 Resize하기 전까지는 성능이 크게 다를바 없었습니다. 그러다 결국 이미지 크기를 바꿔주니까 성능이 향상되었는데 이번 주말동안 pretrain모델로 사용하기 적합해 보이는 모델들을 골라 논문도 좀 읽어보고 더 적절한 structure를 고민해 봐야할 것 같습니다.
느낀 점 및 진행상황
우선 앞에서 eval한 결과를 눈으로 봤을 때는, 대체로 나이 구분을 잘 못하고 있는 경향이 관찰되었습니다. 그래서 데이터 전처리 쪽에서 저는 Cutmix를 고민하고 있는 상황이며 팀원들 중 전처리를 주로 맡고 있는 분들은 Face detection을 생각하고 있습니다. 솔직히 지금은 어떤 곳에서 개선을 하는 것이 정답인지는 잘 모르겠습니다. 이것저것 해봐야 알 수 있을 것 같습니다.