
부스트캠프에서 새롭게 알게 된 사실들
4-2강 Module and Project
pycache 폴더
기계어로 번역된 컴파일된 파일들을 모아놓는 곳
모듈을 불러오는 여러가지 방법
import 모듈
from 모듈 import 함수 or 클래스
from 패키지 import 모듈
if __name__ == ‘__main__’:
파일 안에 다음과 같이 작성을 하면, if 문 안에 속하는 코드는 오직 이 파일을 직접 실행시켰을 때만 동작한다
print("hi thank you for importing me")
if __name__ == '__main__':
print("to be honest i don't hahahaha")
__init__.py와 __main__.py
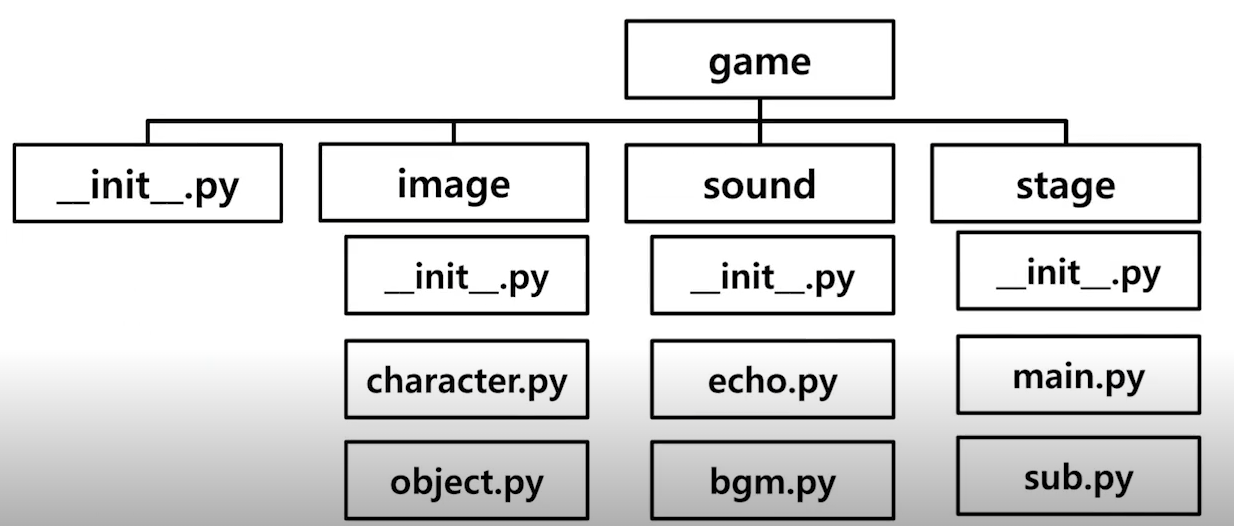
__init__.py
- 현대 폴더가 패키지임을 알리는 초기화 스크립트
- 3.3 버전 이후에는 없어도 무방
- import와 __all__ keyword 사용
# __init__.py
__all__ = ["하위 폴더1(모듈)", "하위 폴더2(모듈)", ..]
from . import 하위 폴더1
from . import 하위 폴더2
__main__.py
- 패키지명으로 실행되는 파일
# __main__.py
from 서브폴더 import 모듈명
# 이 부분이 필수는 아니지만 다른 곳에서 이 패키지를 임포트했을 때 실행되지 않았으면 하는 부분은 여기에 넣으면 된다
if __name__ == '__main__':
print(모듈명.함수(100))
5-1강 File / Exception / Log Handling
Exception Handling
if - else vs try - except else - finally
# 파이썬에서는 if - else를 통한 예외 처리보다 try-except를 이용한 예외처리를 권장한다
# except문이 실행되도 코드가 끝나는 건 아니다 for문 안에 있을 경우 for문을 마저 계속 돌린다
try:
...
except 에러:
...
# 어떤 에러인지 알고 싶을 때
try:
...
except 에러 as e:
print(e)
# 모든 에러를 잡아준다 ( IndexEroor, ValueError, ...)
try:
...
except Exception as e:
print(e)
try:
...
except:
...
# try, except에서 다 걸리지 않으면 else문 실행
else:
...
# 어떤 경우데도 finally 실행된다
# [try or except or else] + finally
try:
...
except:
...
else:
...
finally:
...
코드 중단 시키기: raise vs assert
프로그램이 끝날 때까지 시간이 오래 걸리거나, 리소스가 많이 필요한 경우 에러가 발생했을 때는 프로그램이 종료되도록 하는 것이 좋다.
while True:
value = input("숫자를 입력하세요:")
for digit in value:
if digit not in "0123456789":
raise ValueError("숫자값을 입력하지 않았습니다")
print("정수값", int(value))
break
def get_binary_number(decimal_number):
assert isinstance(decimal_number, int)
return bin(decimal_number)
print(get_binary_number(10.0))
--------------------------------------
AssertionError
File
텍스트 파일
- 인간도 이해할 수 있는 문자열 형식으로 저장된 파일
- 메모장으로 열면 내용 확인 가능
- 메모장에 저장된 파일, HTML파일, 파이썬 코드 파일 등
Binary 파일
- 컴퓨터만 이해할 수 있는 이진형식으로 저장된 파일
- 일반적으로 메모장으로 열면 내용이 깨져 보임
- (이진 파일도 이진 파일을 지원하는 프로그램으로 열어야 이진법으로 보인다)
- 엑셀파일, 워드 파일 등
파일 Read & Write
파일 Read
f = open("파일 이름", "모드")
f.close()
# 파일 읽어오기
f = open("i_have_a_dream.txt", "r")
contents = f.read()
print(contents)
f.close
# with 구문 이용하기
with open("i_have_a_dream.txt", "r") as f:
contents = f.read()
print(contents)
# 파일을 한 줄씩 리스트에 저장해서 리스트 자료형으로 반환
with open("i_have_a_dream.txt", "r") as f:
content_list = f.readlines()
print(content_list)
# 실행마다 한 줄씩 읽어오기
with open("i_have_a_dream.txt", "r") as f:
i = 0
while True:
line = my_file.readline()
if not line:
break
print (str(i) + " === " + line.replace("\n", ""))
i = i + 1
파일 Write
# w모드는 새로 작성 a모드는 추가하기
with open("count_log.txt", "w", encoding="utf8") as f:
for i in range(1, 11):
data = "%d번 째 줄입니다.\n" % i
f.write(data)
모듈을 이용한 파일과 디렉토리 다루기
os모듈
try:
os.mkdir("log")
except FileExistsError as e:
print("Already created")
os.path.exists("log")
----------------------------
True
pickle 모듈
- pickle은 파이썬에 특화된 바이너리 파일
- 파이썬 객체는 보통 메모리에 있다가 프로세스 종료되면 메모리에서 사라진다
- pickle을 쓰면 파이썬 객체를 디스크에 파일로 저장할 수 있다
- 한마디로 pickle은 파이썬의 객체를 영속화(persistence)하는 built-in 객체이다
import pickle
f = open("list.pickle", "rb")
test_pickle = pickle.load(f)
print(test_pickle)
f.close()
import pickle
f = open("list.pickle", "wb")
test = [1, 2, 3, 4, 5]
pickle.dump(test, f)
f.close
Logging Handling
로그 남기기
- 유저의 접근, 프로그램의 Exception, 특정 함수의 사용에 관해 로그 남길 수 있다
- Console 화면에 출력할 수도 있고, 파일이나 데이터베이스에 저장할 수도 있다.
- 출력만 하는 것은 확인할 수는 있지만 분석에 이용할 수는 없다.
logging 모듈
프로그램 실행 설정하기
configparser
- Section, key, value의 형태로 파일 작성
- 설정파일을 딕셔너리 타입으로 호출 후 사용
# config file
# example.cfg
[SectionOne]
Status: Single
Name: Derek
Value: Yes
Age: 30
[SectionTwo]
FavoriteColor = Green
# configparser file
import configparser
config = configparser.ConfigParser()
config.read('example.cfg')
config.sections()
for key in config['SectionOne']:
value = config['SectionOne'][key]
print(f"{key}: {value}")
config['SectionOne']["status"]
argparser
- 콘솔창에서 프로그램 실행시 값 설정
# arg_sum.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('-a', '--a_value', type=int)
parser.add_argument('-b', '--b_value', type=int)
args = parser.parse_args()
print(args)
print(args.a)
print(args.b)
print(args.a + args.b)
python arg_sum.py -a 10 -b 10
-----------------------------------
Namespace(a=10, b=10)
10
10
20
다음과 같이 파일을 만들면 파이썬 파일 실행 시 하이퍼 파라미터 값들을 설정할 수 있다

5-2강 Python data handling
CSV
- 엑셀 파일 -> .xlsx 파일 형태, 엑셀 프로그램에서 읽을 수 있음
-
텍스트 파일 -> .csv 파일 형태, .txt 파일 형태, 엑셀, 메모장, 리눅스 쉘 등에서 읽을 수 있음
- 텍스트 파일 처리시 문장내에 들어 있는 “,” 등에 대한 전처리 과정이 필요해 보통 open()이 아닌 csv객체를 생성하는 것이 낫다.
- 가장 압도적으로 많이 사용하는 방법은 판다스를 통해 데이터를 불러오는 것이다(pd.read_csv())
파일 읽기
import csv
# 보통 윈도우에서 저장 관리되는 파일들은 cp949로 인코딩되어 저장 관리된다.
# 근데 vscode에서는 파일들을 utf-8로 인코딩하기 때문에 cp949로 인코딩해야 한다
with open("korea_foot_traffic_data.csv", "r", encoding="cp949") as p_file:
csv_data = csv.reader(p_file)
for row in csv_data:
...
파일 쓰기
import csv
seoung_name_data = []
header = []
rownum = 0
with open("seoung_nam_foot_traffic_data.csv", "w", encoding="utf8") as s_p_file:
writer = csv.writer(s_p_file, delimiter = '\t', quotechar="'", quoting=csv.QUOTE_ALL)
writer.writerow(header)
for row in seoung_nam_data:
writer.writerow(row)
...
Web
- 인터넷 망을 World Wide Web(WWW), Web이라 부른다
- 데이터 송수신을 위한 HTTP 프로토콜 사용
- 데이터의 표시 방법을 통일하기 위해 HTML 형식 사용
HTML
- 웹 상의 정보를 구조적으로 표기하기 위한 언어
- 제목, 단락, 링크 등 요소들을 Tag로 구분
- 모든 요소들은 꺽쇠 괄호로 표시된 Tag로 둘러 쌓여 있음
- 웹은 거의 모든 정보가 담겨 있는 공간이므로 이 공간에 HTML 형식으로 저장된 파일을 잘 다룰 수 있어야 의미 있는 데이터를 추출할 수 있다
Data parsing
- 정규표현식으로 Parsing이 가능함
- 그러다 좀 더 손쉬운 도구들이 많이 개발되었음
- 대표적으로 lxml, beautifulsoup이 있음
BeautifulSoup
- HTML, XML과 같은 Markup언어를 Scraping을 위한 대표적인 도구
- lxml과 html5lib와 같은 Parser를 wrapping한 도구
- 속도는 상대적으로 느리지만 간편히 사용할 수 있음
from bs4 import BeautifulSoup
# 객체 생성
soup = BeautifulSoup(books_xml, "lxml")
# author라는 태그가 들어간 데이터 모두 찾아주는 find_all() 메소드
for book_info in soup.find_all("author"):
print(book_info)
print(book_info.get_text())
------------------------------------------------
<author>Carson</author>
Carson
<author>Sungchul</author>
Sungchoul
JSON(JavaScript Object Notation)
- 웹 언어인 Java Script의 데이터 객체 표현 방식
- 간결성으로 기계/인간이 모두 이해하기 편함
- 데이터 용량이 적음
- XML의 대체제로 많이 활용
- 파이썬에서는 json모듈을 사용해 손쉽게 데이터 파싱 및 저장 가능

파일 읽기 json.loads()
# json_example.json
{"employees": [
{"firstName": "John", "lastNmae": "Doe"},
{"firstName": "Anna", "lastNmae": "Smith"},
{"firstName": "Peter", "lastNmae": "Mike"},
]}
import json
with open("json_example.json", "r", encoding="utf8") as f:
contents = f.read()
json_data = json.loads(contents)
print(json_data["employees"])
------------------------------------------------------
[
{"firstName": "John", "lastNmae": "Doe"},
{"firstName": "Anna", "lastNmae": "Smith"},
{"firstName": "Peter", "lastNmae": "Mike"},
]
파일 쓰기: json.dump()
import json
dict_data = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
with open("data.json", "w") as f:
json.dump(dict_data, f)