부스트캠프에서 새롭게 알게 된 사실들
1. Optimizer
1) 그래디언트 모멘텀(Gradient Momentum)
모멘텀은 학습을 좀 더 안정감 있게 하도록 해줍니다. 데이터에 의해 Gradient를 계산할 때 만약 Noisy한 데이터인 경우, Gradient가 잘못된 방향으로 갈 가능성이 큽니다. 그렇기 때문에 그 동안 누적된 Gradient를 감안하여 Gradient가 Noisy한 데이터에 의한 안 좋은 영향을 줄여준다. 영어로 잘 설명된 부분이 있어 가져와 보았습니다.
Momentum method can accelelerate gradient descent by taking accounts of previous gradients in the update rule equation in every iteration


2) 적응적 학습률(Adaptive Learning-rate)
가중치 업데이트의 척도가 되는 학습률을 각 가중치의 학습 진행 정도에 따라 다르게 바꿔주는 것을 적응적 학습률이라고 한다.
적응적 학습률은
가중치의 업데이트가 많이 이루어질수록 점점 학습률을 줄여나간다.
특성마다 업데이트가 많이 된 특성은 학습률을 줄이고, 적게된 특성은 학습률을 늘린다.

2. Advanced CNN
1. GoogLeNet
1) GoogLeNet의 특징
- 커널의 적절한 사이즈를 찾기 위해 고민하기 보다, 여러 가지 사이즈의 커널을 병렬로 이용함으로써 보다 풍부한 Feature Extraction 수행한다
- 1 X 1 컨볼루션 필터를 이용해 Feature map의 dimension을 줄이고, 결과적으로 연산해야 할 파라미터 수를 감소시킨다.
- 1 X 1 이라서 Feature map dimension이 줄어든 것이 아니라, 1 X 1 필터의 채널 수를 작은 사이즈를 썼기 때문이다.
- 참고로 컨볼루션 커널의 사이즈, padding, striding이 Feature map의 사이즈를 결정한다.
- 컨볼루션 커널의 채널의 개수가 Feature map의 개수를 결정한다.
2) Inception Module
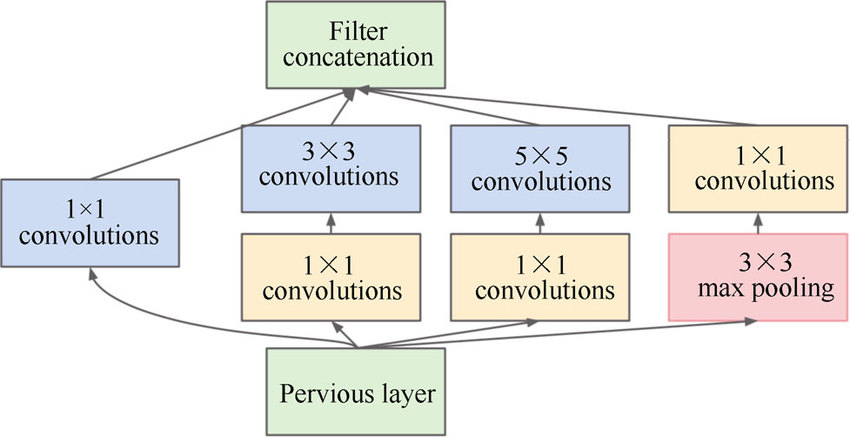
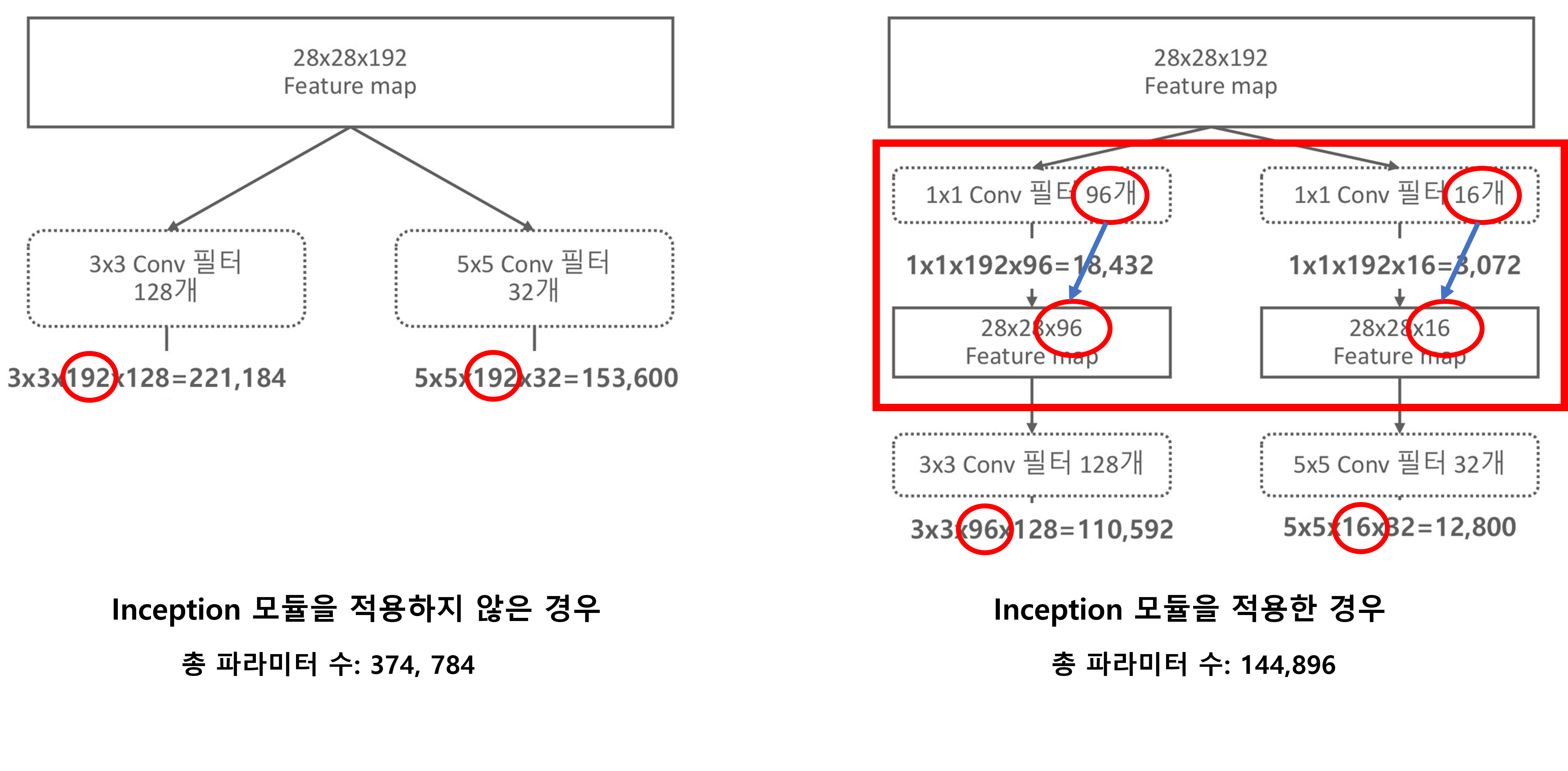
- 위 그림과 같이 1 X 1 컨볼루션 필터를 이용해 Feature map의 dimension을 줄이고, 결과적으로 연산해야 할 파라미터 수를 감소시켰다.
- Inception모듈을 보면 여러 필터가 병렬적으로 연산되고 모듈 끝에서 결과들이 Concatenation됩니다.
- 따라서 Feature map의 개수는 달라도 괜찮지만, Feature map의 사이즈는 같아야 합니다.
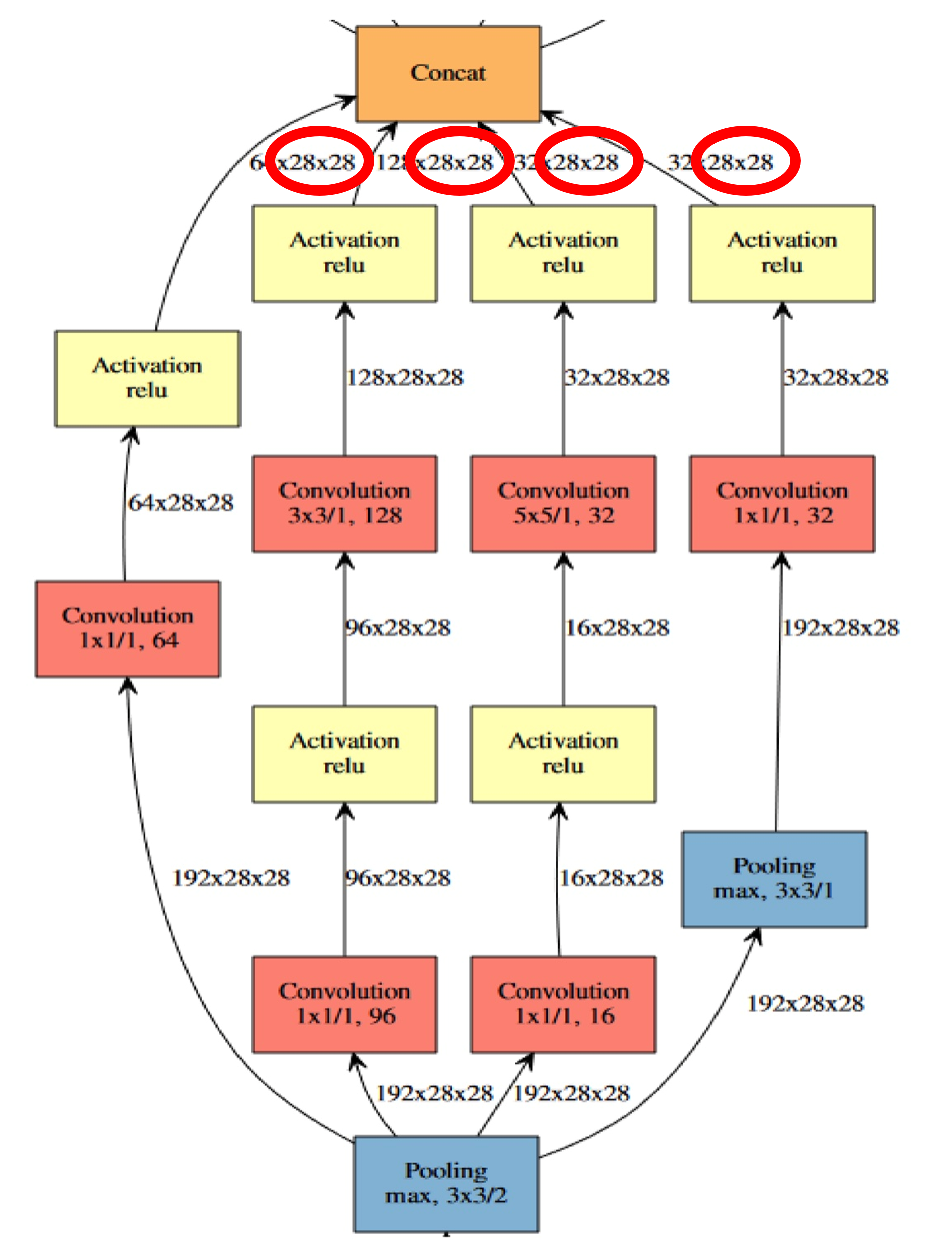
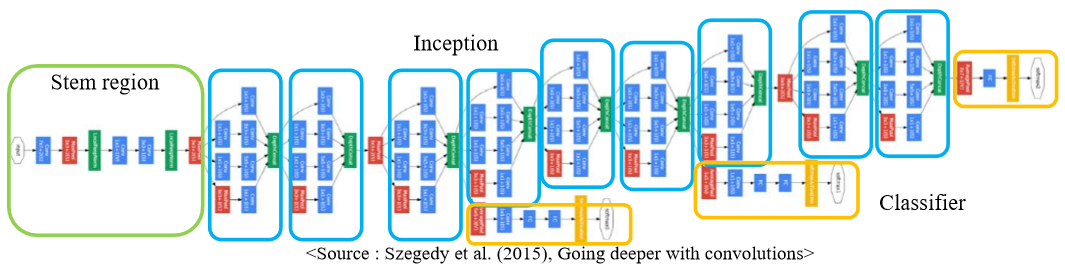
3) GoogLeNet Network Structure
- 다음과 같이 Inception Module은 총 9개로 구성되어 있다
- Concatenation까지가 Inception Module에 포함되고 그 후에 보통 Pooling layer를 거친 뒤 다시 Inception Module로 들어가는 것으로 반복된다.
- Inception Module을 2개 거친 후 Pooling하기도 하고, 5개 거치고 Pooling 하기도 한다.
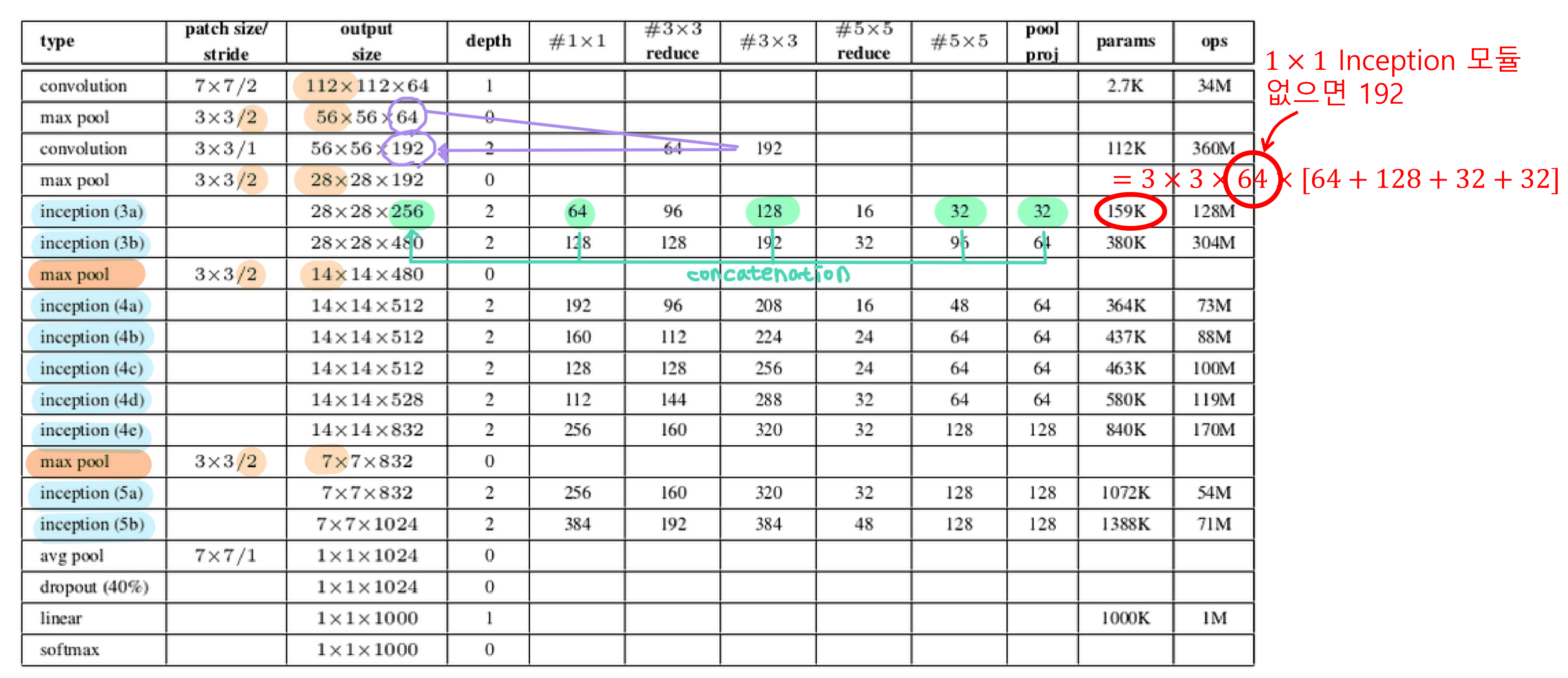
2. ResNet
- VGG 모델이 나온 이후 깊은 Network가 좋은 성능을 낸다는 인식이 생겼다.
- 하지만 비슷한 방식으로 Network를 더 깊게 만들었을 때 오히려 성능이 저하되었다.
- 그 원인으로는 Gradient Vanishing과 파라미터 수 증가에 따른 학습 속도 저하가 있다.
- 파라미터 수 증가는 앞에서와 같이 1 X 1 컨볼루션으로 해결하였다.
- Gradient Vanishing 문제는 Residual Learning을 통해 해결하였다.
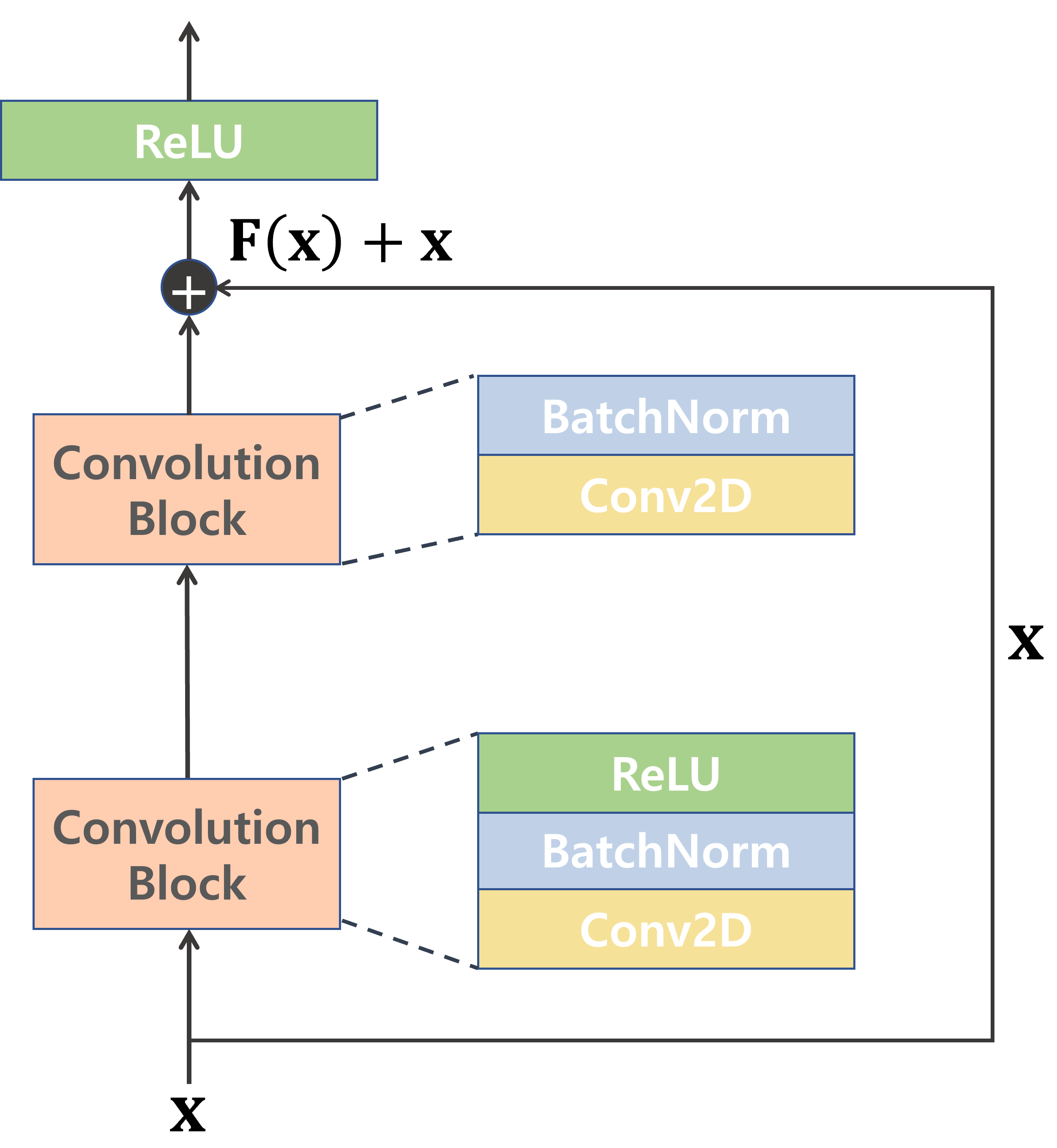
1) Residual Learning
- 처음 Residual Learning이 나오기 전에 시도되던 방법은 Identity mapping이다.
- Identity mapping은 층은 더 깊게 만들되, Gradient vanishing은 생기지 않도록 하기 위해 이전 값을 그대로 다시 통과시키는 방법이다.
- 비선형성은 있어야 층을 깊게 쌓는 의미가 있으므로 Relu()정도가 있어야 하는데, 이렇게 되면 identity한 mapping이 되기 어려워진다.
- 그래서 좀 더 쉬운 방법으로 제안된 것이 Residual Learning이다.
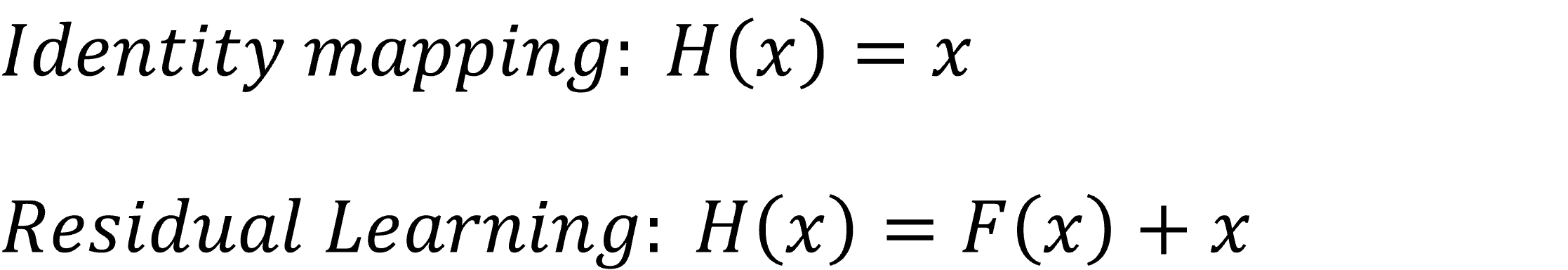
- H(x)가 x가 되도록 하는 것이 아니라, F(x)가 0이 되도록 학습하는 것이 쉽다.
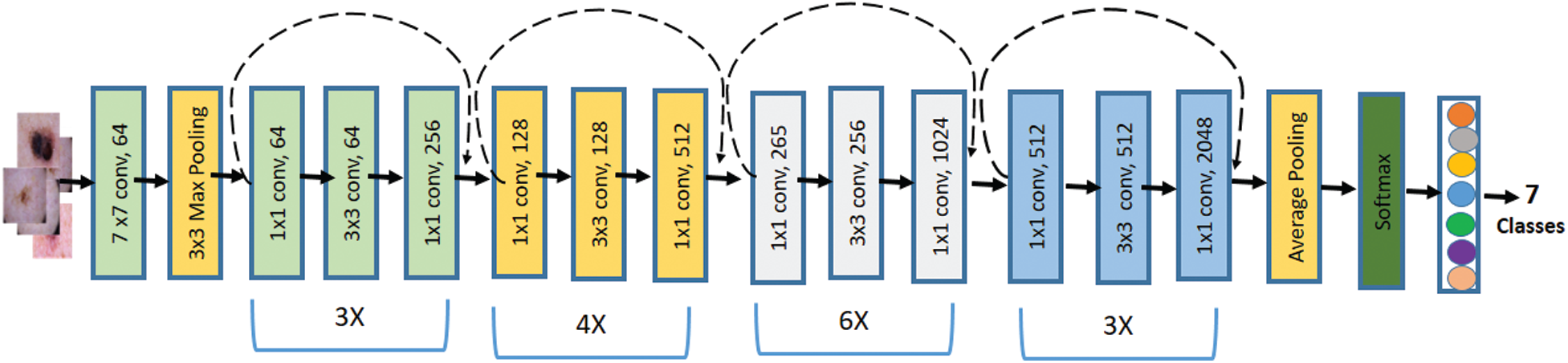
2) Residual Block
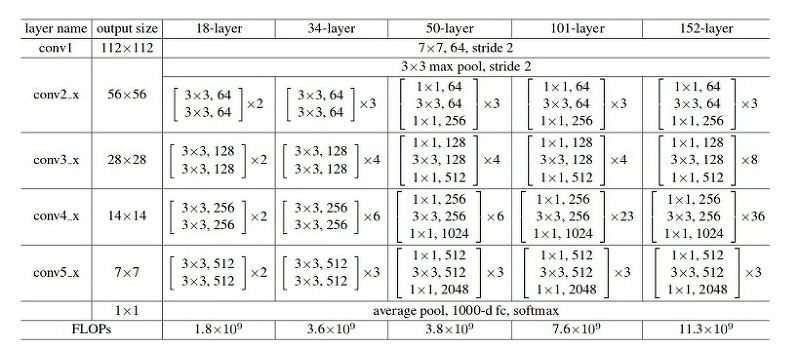
- ResNet 50을 포함한 이보다 깊은 네트워크(50/101/152)에서는 1 X 1 Conv를 이용해 파라미터 갯수를 줄였다.
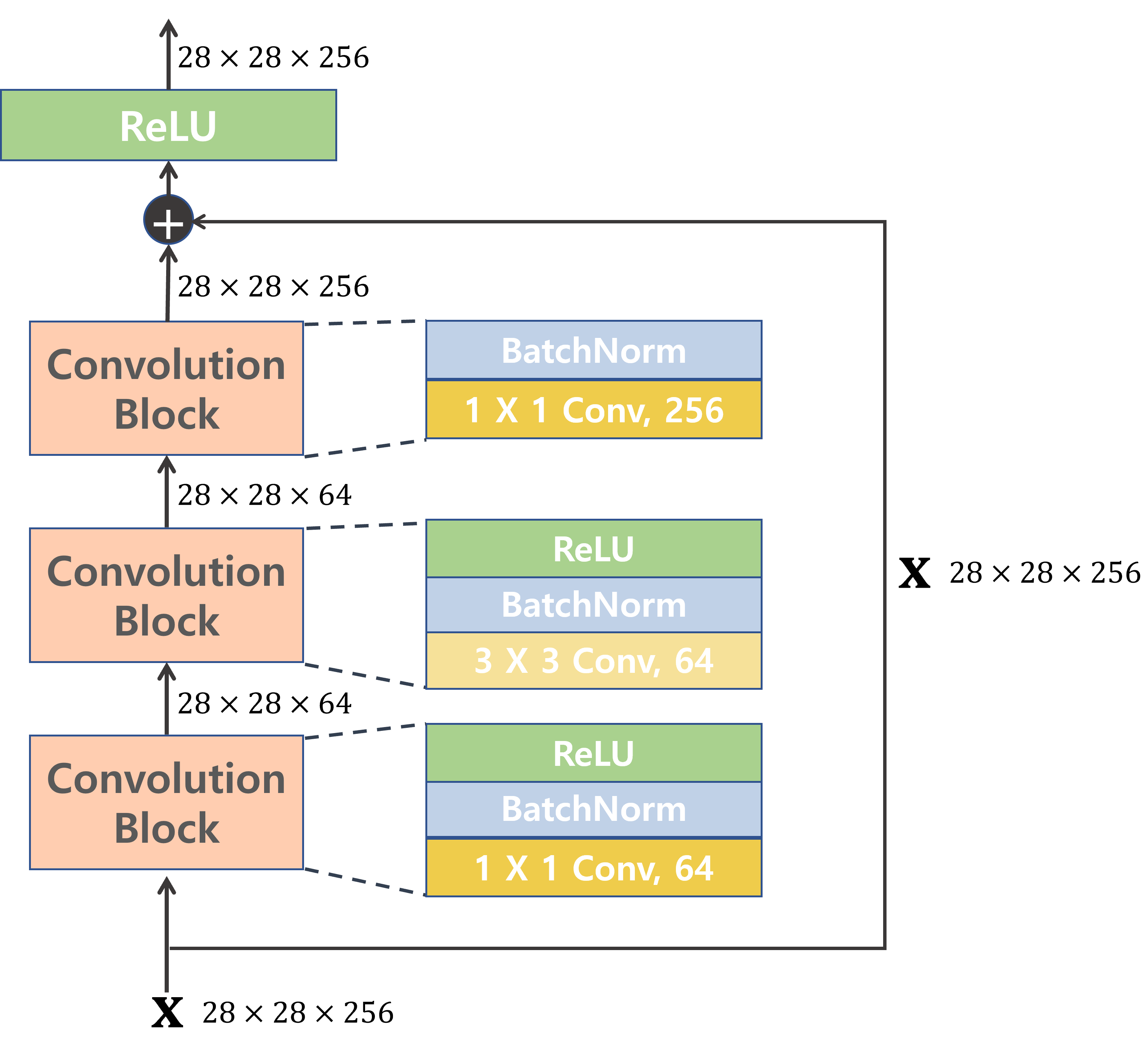
- Residual Block 내에서는 Feature map 사이즈는 동일하고 Filter수만 변함
3) ResNet Architecture