
1. 케라스 소개
케라스는 모든 종류의 신경망을 손쉽게 만들고 훈련, 평가, 실행할 수 있는 고수준 딥러닝 API입니다. 다음의 3가지 인기있는 딥러닝 라이브러리 텐서플로, 마이크로소프트 코그니티브 툴킷, 시애노 중에 하나를 백엔드로 선택해 케라스 API를 사용할 수 있습니다. 그 중에서도 텐서플로는 자체적인 케라스 구현인 tf.keras를 번들로 포함하며 이는 효율적인 데이터 적재와 전처리를 간편하게 수행할 수 있는 텐서플로 데이터 API를 지원합니다. 이런 이유로 저는 여기서 tf.keras를 사용하도록 하겠습니다.
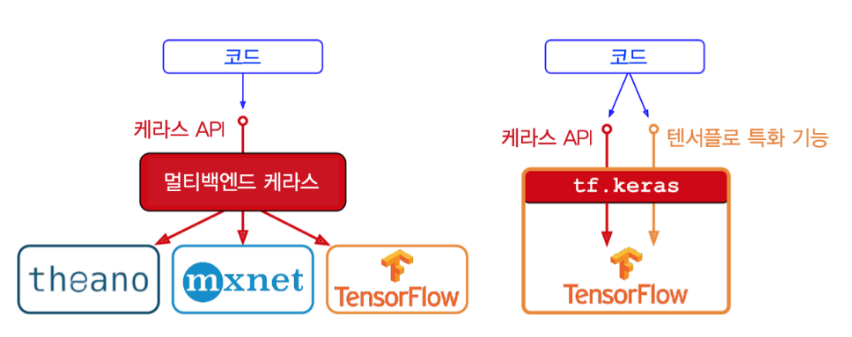
(출처: 핸즈온 머신러닝)
2. 모델 구축
Sequeitial API
- 두 개의 은닉층으로 이루어진 분류용 다층 퍼셉트론을 만들어보겠습니다.
model = keras.models.Sequential() model.add(keras.layers.Flatten(input_shape=[28, 28])) model.add(keras.layers.Dense(300, activation='relu')) model.add(keras.layers.Dense(100, activation='relu')) model.add(keras.layers.Dense(10, activation='softmax')) - 하나씩 추가하지 않고 층의 리스트를 전달하는 방법을 통해 모델을 만들어 보겠습니다.
keras.models.Sequential([keras.layers.Flatten(input_shpae=[28. 28]), keras.layers.Dense(300, activation='relu'), keras.layers.Dense(100, activation='relu'), keras.layers.Dense(10, activation='softmax')]) - summary()메소드는 모델에 있는 모든 층을 출력합니다.
>>> model.summary() Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten (Flatten) (None, 784) 0 _________________________________________________________________ dense (Dense) (None, 300) 235500 _________________________________________________________________ dense_1 (Dense) (None, 100) 30100 _________________________________________________________________ dense_2 (Dense) (None, 10) 1010 ================================================================= Total params: 266,610 Trainable params: 266,610 Non-trainable params: 0 _________________________________________________________________ - keras.utils.plot_model()함수를 사용하여 모델 구조를 이미지로 출력할 수 있습니다.
>>> keras.utils.plot_model(model, "my_fashion_mnist_model.png", show_shapes=True)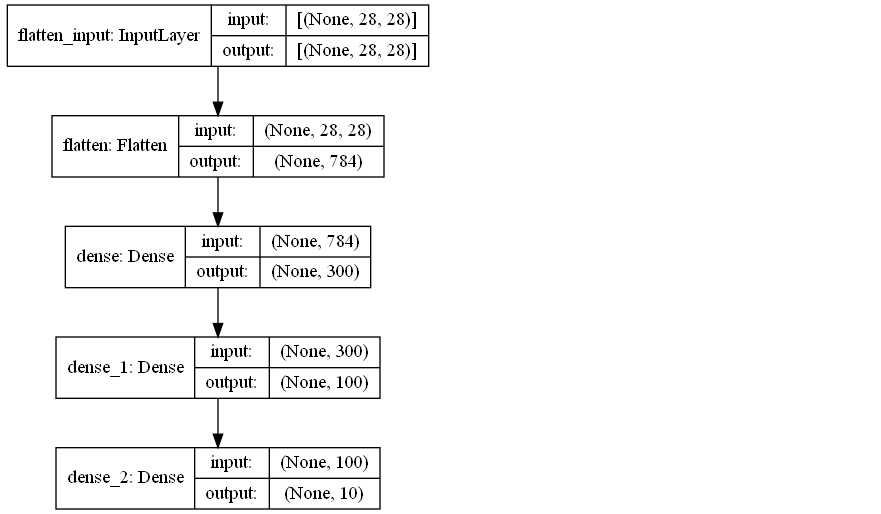
- 모델에 있는 층의 리스트를 출력하거나 인덱스 또는 이름으로 층을 선택할 수 있습니다.
# 모델에 있는층의 리스트 출력 >>> model.layers [<tensorflow.python.keras.layers.core.Flatten at 0x215574584c8>, <tensorflow.python.keras.layers.core.Dense at 0x21557458748>, <tensorflow.python.keras.layers.core.Dense at 0x21557458bc8>, <tensorflow.python.keras.layers.core.Dense at 0x21557455248>] # 인덱스 또는 이름으로 접근 >>> hidden1 = model.layers[1] >>> hidden1.name 'dense' # 층을 만들 떄 이름을 따로 지정하지 않아 자동으로 생성되었다 - 층의 모든 파라미터에 접근할 수 있습니다.
>>> weights, biases = hidden1.get_weights() >>> weights array([[ 0.02448617, -0.00877795, -0.02189048, ..., -0.02766046, 0.03859074, -0.06889391], ..., [-0.03048757, 0.02155137, -0.05400612, ..., -0.00113463, 0.00228987, 0.05581069], [-0.06022581, 0.01577859, -0.02585464, ..., -0.00527829, 0.00272203, -0.06793761]], dtype=float32) >>> biases array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32) >>> weights.shape (784, 300) - 컴파일 (loss, optimizer, metrics)을 통해 손실 함수와 옵티마이저, 평가 지표를 지정할 수 있습니다.
model.compile(loss='sparse_categorical_crossentropy', optimizer='sgd', metrics=['accuracy']) - 모델 훈련
>>> history = model.fit(X_train, y_train, epochs=30, validation_data = (X_valid, y_valid)) Epoch 26/30 1719/1719 [==============================] - 3s 2ms/step - loss: 0.2422 - accuracy: 0.9135 - val_loss: 0.3091 - val_accuracy: 0.8892 Epoch 27/30 1719/1719 [==============================] - 3s 2ms/step - loss: 0.2369 - accuracy: 0.9158 - val_loss: 0.3002 - val_accuracy: 0.8960 Epoch 28/30 1719/1719 [==============================] - 3s 2ms/step - loss: 0.2316 - accuracy: 0.9169 - val_loss: 0.3018 - val_accuracy: 0.8922 Epoch 29/30 1719/1719 [==============================] - 3s 2ms/step - loss: 0.2280 - accuracy: 0.9172 - val_loss: 0.3044 - val_accuracy: 0.8892 Epoch 30/30 1719/1719 [==============================] - 3s 2ms/step - loss: 0.2251 - accuracy: 0.9204 - val_loss: 0.3045 - val_accuracy: 0.8910 - 학습 곡선
fit() 메소드가 반환하는 History 객체에는 에포크가 끝날 때마다 훈련세트와 검증 세트에 대한 손실과 측정한 지표를 담은 딕셔너리(history.history)가 있습니다. 이 딕셔너리를 사용해 판다스 데이터프레임을 만들고 plot()메소드를 호출하면 학습 곡선을 볼 수 있습니다.import pandas as pd import matplotlib as plt pd.DataFrame(history.history).plot(figsize=(8, 5)) plt.grid(True) plt.gca().set_ylim(0, 1) plt.show()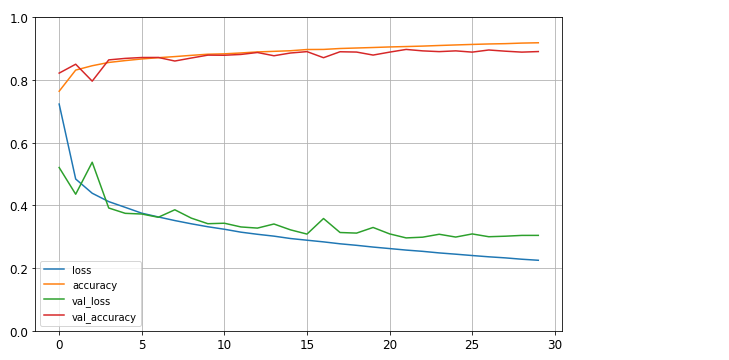
- 모델 평가
모델의 검증 정확도가 만족스럽다면 모델을 배포하기 전에 테스트 세트로 모델을 평가합니다. 이때 evaluate() 메소드를 사용합니다.>>> model.evaluate(X_test, y_test) 313/313 [==============================] - 0s 1ms/step - loss: 0.3367 - accuracy: 0.8819 - 모델 사용해 예측 만들기
predict()메소드를 사용해 새로운 샘플에 대해 예측을 만들 수 있습니다.>>> X_new = X_test[:3] >>>> y_proba = model.predict(X_new) >>> y_proba.round(2) array([[0. , 0. , 0. , 0. , 0. , 0.01, 0. , 0.03, 0. , 0.96], [0. , 0. , 0.99, 0. , 0.01, 0. , 0. , 0. , 0. , 0. ], [0. , 1. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ]], dtype=float32) >>> y_pred = np.argmax(model.predict(X_new), axis=-1) >>> y_pred array([9, 2, 1], dtype=int64)
함수형 API
함수형 API를 사용하면 입력과 출력을 여러개로 두거나 경로를 여러개로 둘 수 있습니다.
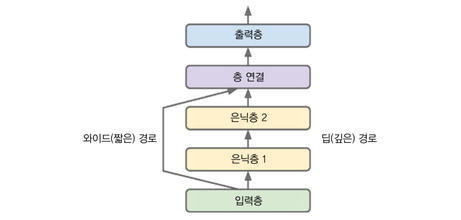
input_ = keras.layers.Input(shape=X_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation="relu")(input_)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs=[input_], outputs=[output])
- 입력과 출력이 여러 개인 구조
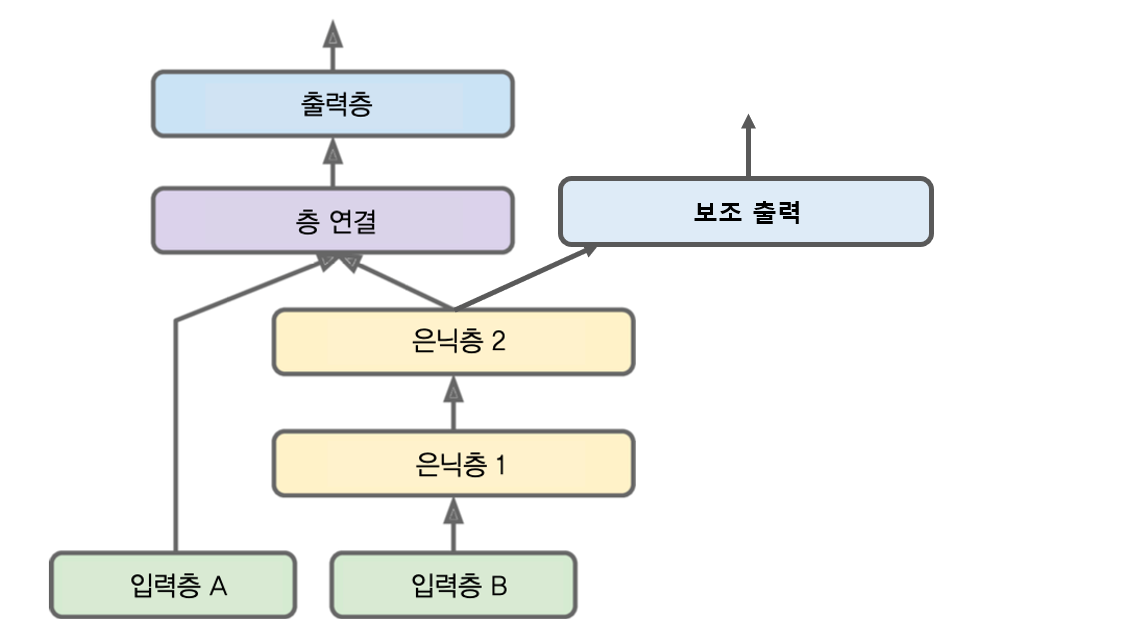
input_A = keras.layers.Input(shape=[5], name="wide_input") input_B = keras.layers.Input(shape=[6], name="deep_input") hidden1 = keras.layers.Dense(30, activation="relu")(input_B) hidden2 = keras.layers.Dense(30, activation="relu")(hidden1) concat = keras.layers.concatenate([input_A, hidden2]) output = keras.layers.Dense(1, name="main_output")(concat) aux_output = keras.layers.Dense(1, name="aux_output")(hidden2) model = keras.models.Model(inputs=[input_A, input_B], outputs=[output, aux_output]) - 모델 컴파일 및 학습
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3)) #각 출력의 손실 함수를 따로 정해줄 수도 있다, 주 출력의 손실에 더 많은 가중치 부여할 수도 있다. model.compile(loss=["mse", "mse"], loss+weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(lr=1e-3)) X_train_A, X_train_B = X_train[:, :5], X_train[:, 2:] X_valid_A, X_valid_B = X_valid[:, :5], X_valid[:, 2:] X_test_A, X_test_B = X_test[:, :5], X_test[:, 2:] X_new_A, X_new_B = X_test_A[:3], X_test_B[:3] history = model.fit((X_train_A, X_train_B), y_train, epochs=20, validation_data=((X_valid_A, X_valid_B), y_valid)) mse_test = model.evaluate((X_test_A, X_test_B), y_test) y_pred = model.predict((X_new_A, X_new_B)) - 모델 평가
각 출력의 개별 손실과, 총 손실을 반환합니다.total_loss, main_loss, aux_loss = model.evaluate( [X_test_A, X_test_B], [y_test, y_test]) y_pred_main, y_pred_aux = model.predict([X_new_A, X_new_B])
서브클래싱 API
시퀀셜 API와 함수형 API는 모두 선언적입니다. 사용할 층과 연결 방식을 먼저 정의해야 합니다. 이 방식은 모델을 저장하거나 복사, 공유하기 쉽습니다. 하지만 단점도 있습니다. 어떤 모델은 반복문을 포함하고 다양한 크기를 다루어야 하며 조건문을 가지는 등 여러 가지 동적인 구조를 필요로 합니다. 이런 경우 서브클래싱 API가 정답입니다. 간단히 Model 클래스를 상속한 다음 생성자 안에서 필요한 층을 만듭니다. 그 다음 call()메소드 안에 수행하려는 연산을 기술합니다.
class WideAndDeepModel(keras.models.Model):
def __init__(self, units=30, activation="relu", **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(units, activation=activation)
self.hidden2 = keras.layers.Dense(units, activation=activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideAndDeepModel(30, activation="relu")
이 예제는 함수형 API와 매우 비슷하지만 주된 차이점은 call()메소드 안에서 원하는 어떤 계산도 사용할 수 있다는 것입니다. for문, if문, 텐서플로 저수준 연산을 사용할 수 있습니다.
# 나머지 컴파일, 학습, 평가 관련 부분
model.compile(loss="mse", loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(lr=1e-3))
history = model.fit((X_train_A, X_train_B), (y_train, y_train), epochs=10,
validation_data=((X_valid_A, X_valid_B), (y_valid, y_valid)))
total_loss, main_loss, aux_loss = model.evaluate((X_test_A, X_test_B), (y_test, y_test))
y_pred_main, y_pred_aux = model.predict((X_new_A, X_new_B))
단점은 유연성이 높아지면 그에 따른 비용이 발생한다는 것입니다. 모델 구조가 call()메소드 안에 숨겨져 있기 때문에 케라스가 이를 쉽게 분석할 수 없습니다. 즉 모델을 저장하거나 복사할 수 없습니다. 따라서 높은 유연성이 필요하지 않는다면 시퀀셜 API와 함수형 API를 사용하는 것이 좋습니다.
3. 콜백을 이용한 모델 저장과 복원
시퀀셜 API와 함수형 API를 사용하면 훈련된 케라스 모델을 저장하는 것은 매우 쉽습니다. 케라스는 HDF5 포맷을 사용해 모든 층의 하이퍼파라미터와 모델 구조 가중치와 편향을 저장합니다.
# 모델 구축
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
# 컴파일, 훈련, 평가
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
# HDF5 포맷을 사용해 저장
model.save("my_keras_model.h5")
# 다른 스크립트에서 모델을 로드
model = keras.models.load_model("my_keras_model.h5")
콜백 사용하기
컴퓨터에 문제가 생겨 모든 것을 잃지 않으려면 훈련 마지막에 모델을 저장하는 것 뿐만 아니라 훈련 도중 일정 간격으로 체크포인트를 저장해야 합니다. fit() 메소드의 callbacks 매개변수를 사용합니다.
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
# 체크포인트를 위한 콜백
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5", save_best_only=True)
history = model.fit(X_train, y_train, epochs=10,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb])
# 최상의 모델로 롤백
model = keras.models.load_model("my_keras_model.h5")
mse_test = model.evaluate(X_test, y_test)
이번에는 조기 종료를 구현하는 EarlyStopping 콜백을 사용해 보겠습니다.
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
# 조기종료를 위한 콜백
early_stopping_cb = keras.callbacks.EarlyStopping(patience=10,
restore_best_weights=True)
history = model.fit(X_train, y_train, epochs=100,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb, early_stopping_cb])
mse_test = model.evaluate(X_test, y_test)
4. 텐서보드를 이용한 훈련 과정 시각화
텐서보드는 매우 좋은 인터렉티브 시각화 도구입니다. 훈련하는 동안 학습 곡선을 그리거나 훈련 통계 분석을 수행할 수 있습니다. 텐서보드는 텐서플로를 설치할 때 자동으로 설치되므로 이미 시스템에 준비되어 있습니다. 텐서보드 서버는 로그 디렉토리를 모니터링하고 자동으로 변경사항을 읽어 그래프를 업데이트 합니다. 일반적으로 텐서보드 서버가 루트 로그 디렉토리를 가리키고 프로그램은 실행할 때마다 다른 서브디렉토리에 이벤트를 기록합니다. 이렇게 하면 복잡하지 않게 하나의 텐서보드 서버가 여러 번 실행한 프로그램의 결과를 시각화하고 비교할 수 있습니다.
먼저 텐서보드 로그를 위해 사용할 루트 로그 디렉토리를 정의합니다. 현재 날짜와 시간을 사용해 실행할 때마다 다른 서브디렉토리 경로를 생성하는 간단한 함수도 만들겠습니다. 테스트하는 하이퍼파라미터 갑과 같은 추가적인 정보를 로그 디렉토리 이름으로 사용할 수 있습니다. 이렇게 하면 텐서보드에서 어떤 로그인지 구분하기 편리합니다.
# 루트 로그 디렉토리 정의
root_logdir = os.path.join(os.curdir, "my_logs")
# 서브디렉토리 경로를 생성하는 함수
def get_run_logdir():
import time
run_id = time.strftime("run_%Y_%m_%d-%H_%M_%S")
return os.path.join(root_logdir, run_id)
run_logdir = get_run_logdir()
run_logdir
# 모델 구축과 컴파일
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
# 케라스의 TensorBoard() 이용
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
history = model.fit(X_train, y_train, epochs=30,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb, tensorboard_cb])
이 코드를 실행하면 TensorBoard()콜백이 로그 디렉토리를 생성합니다(필요하면 부모 디렉토리도 만듭니다). 훈련하는 동안 이벤트 파일을 만들고 서머리를 기록합니다. (일부 하이퍼파라미터를 바꾼 후) 프로그램을 두 번째 실행하고 나면 다음과 비슷한 디렉토리 구조가 생성될 것입니다.

실행마다 하나의 디렉토리가 생성됩니다. 훈련 로그는 프로파일링 트레이스파일도 포함합니다. 텐서보드가 이 파일을 사용해 전체 디바이스에 걸쳐서 모델의 각 부분에서 시간이 얼마나 소요되었는지 보여주므로 성능 병목 지점을 찾는데 도움이 됩니다.
이제 텐서보드 서버를 시작할 차례입니다. 다음 명령을 실행하여 주피터 안에서 텐서보드를 사용할 수 있습니다.
# 텐서보드 확장을 로드
%load_ext tensorboard
#포트 6006에서 텐서보드 서버를 실행하고 접속
%tensorboard --logdir=./my_logs --port=6006
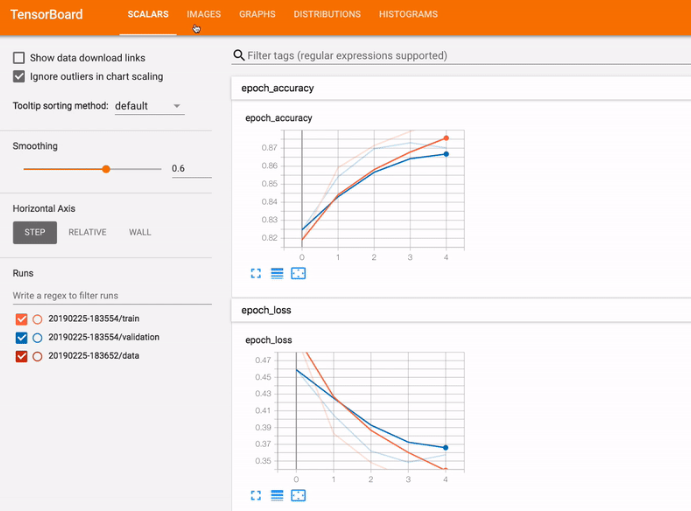
(출처: tensorflow.org/tensorboard)