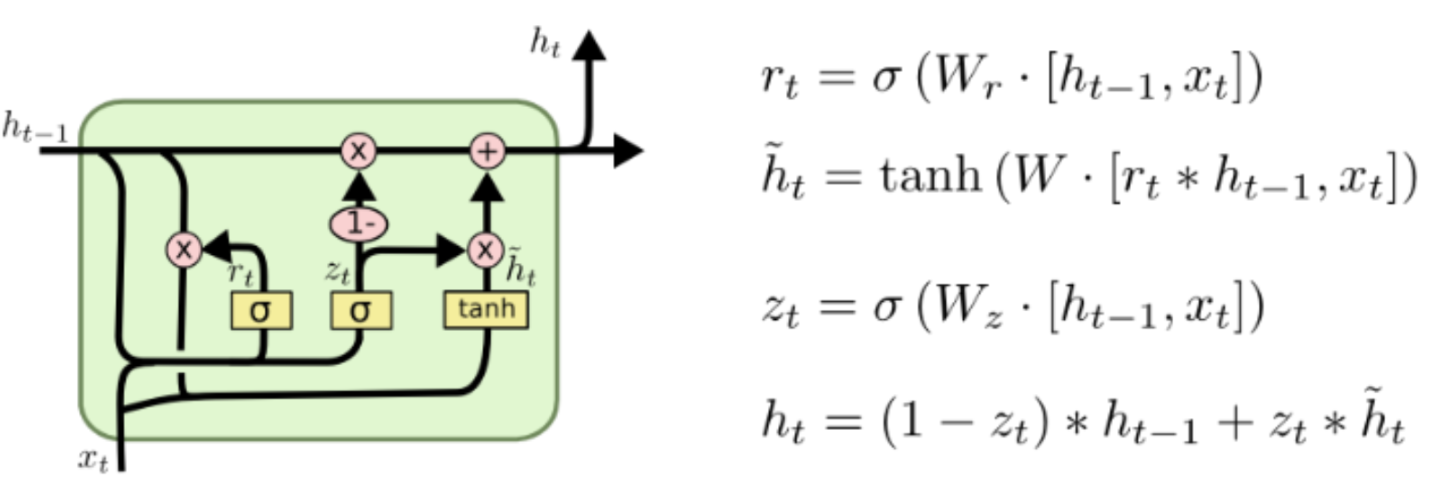
Advanced RNN
바닐라 RNN의 한계점
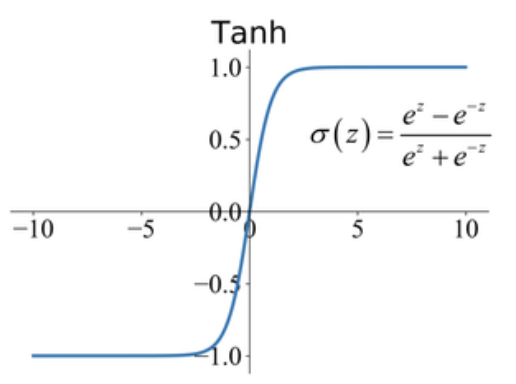
바닐라 RNN은 출력 결과가 이전의 계산 결과에 의존한다는 것을 언급한 바 있습니다. 하지만 바닐라 RNN은 비교적 짧은 시퀀스(sequence)에 대해서만 효과를 보이는 단점이 있습니다. 바닐라 RNN의 시점(time step)이 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생합니다. 그 이유는 다음과 같이 셀을 거듭할수록 tanh함수의 출력값이 가지는 제한(절댓값의 크기가 1보다 같거나 작습니다) 때문입니다. 이를 장기 의존성 문제(the problem of Long-Term Dependencies)라고 합니다.
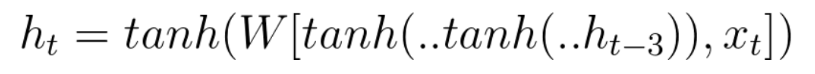
LSTM (Long Short Term Memory)
바닐라 RNN의 한계를 극복하기 위해 다양한 RNN의 변형이 나왔습니다. LSTM과 GRU가 대표적인 예입니다.
긴 시퀀스를 다룰 때 LSTM이 바닐라 RNN과 비교해 어떤 점에서 더 좋은지 알기위해 우선 LSTM의 구조에 대해 먼저 살펴보겠습니다.
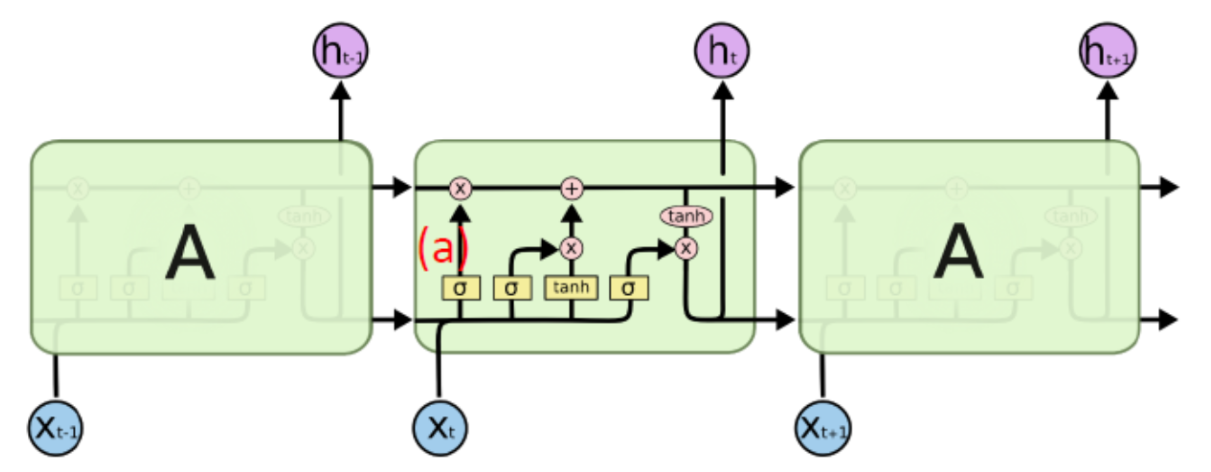
꽤나 복잡하게 생겨서 머리가 아플 수 있지만 하나하나 살펴보면 충분히 가능하기 때문에, 천천히 살펴보도록 하겠습니다.
우선 위로 지나가는 Cell state 부분부터 한번 보겠습니다.
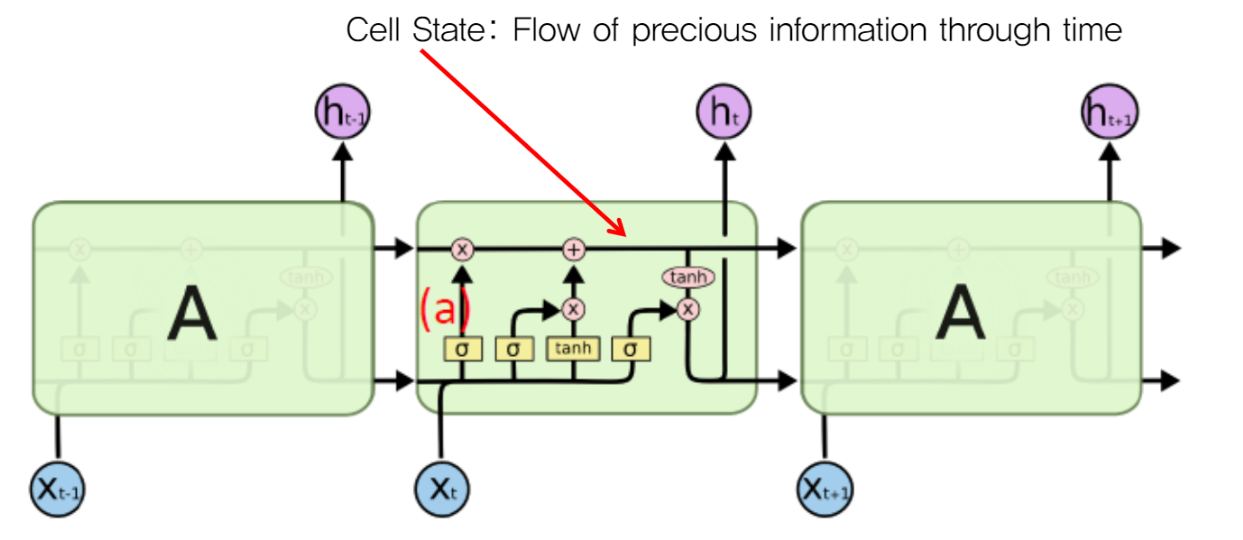
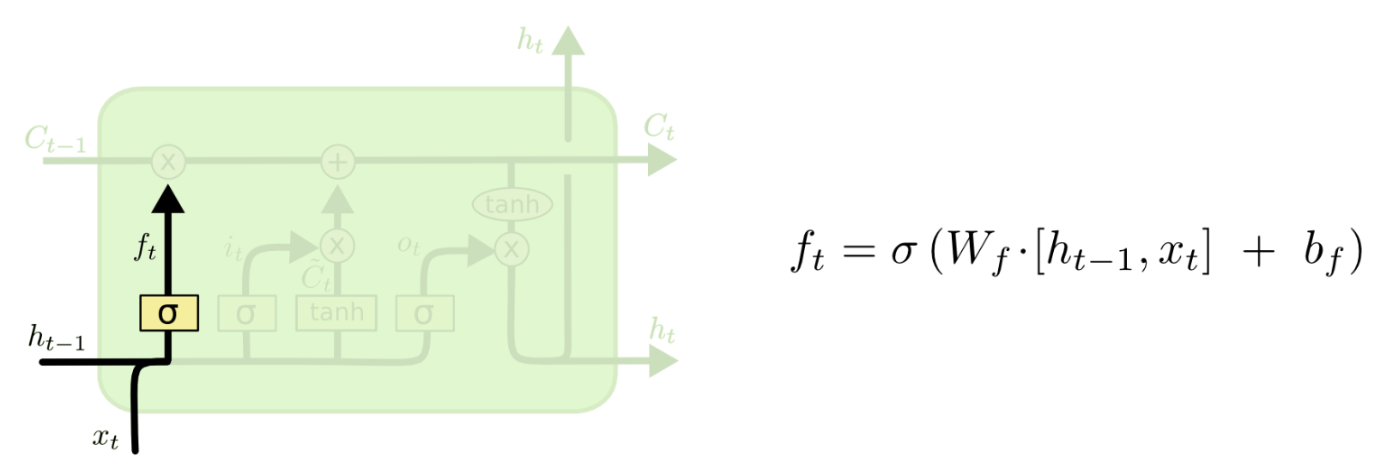
Cell state의 역할은 중요한 정보는 그대로 넘겨주고, 중요하지 않은 정보는 약하게 함으로써 중요한 정보만 계속 흘러갈 수 있도록 해줍니다. 이걸 가능하게 하는 것이 바로 게이트입니다. i(t) 게이트를 통해 중요한 정보는 흘러가고, f(t) 게이트를 통해 중요하지 않은 정보를 약하게 만듭니다. 그러면 어떤 정보가 중요하고 중요하지 않은지는 어떤 기준으로 정해지고 어떻게 설정해야 할까요? 그 기준은 바로 이전 셀의 h(t-1)의 값과 현재 층의 입력 x(t) 으로 정해지며, 설정하는 것은 우리의 몫이 아닌 신경망의 역할입니다. 신경망은 학습을 통해 알아서 중요한 정보와 중요하지 않은 정보를 잘 선택할 수 있도록 학습됩니다.
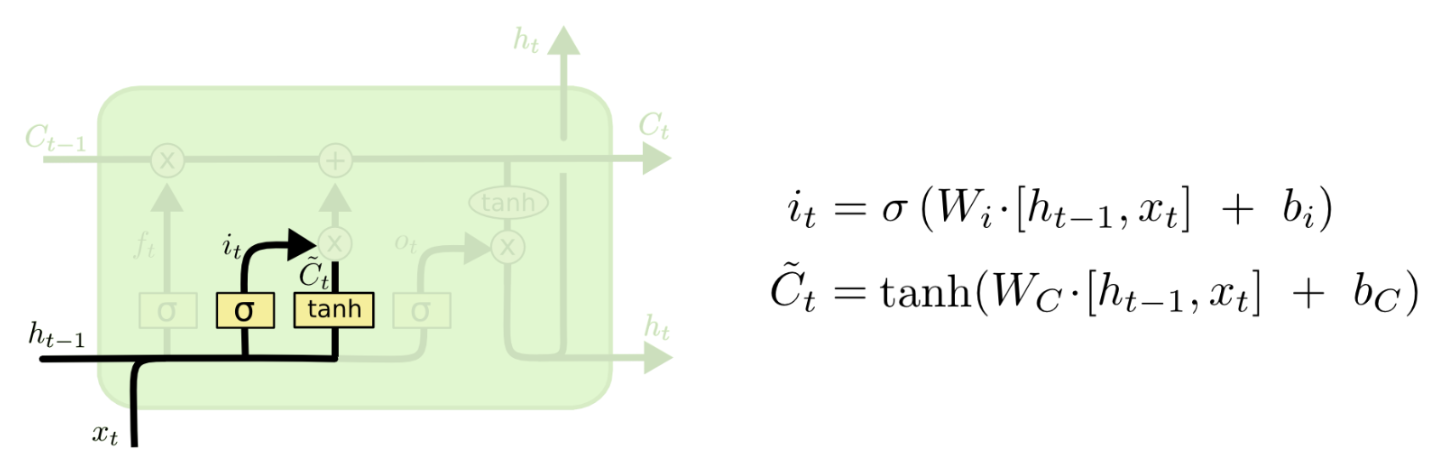
위 과정을 통해 C(t)를 만듭니다.
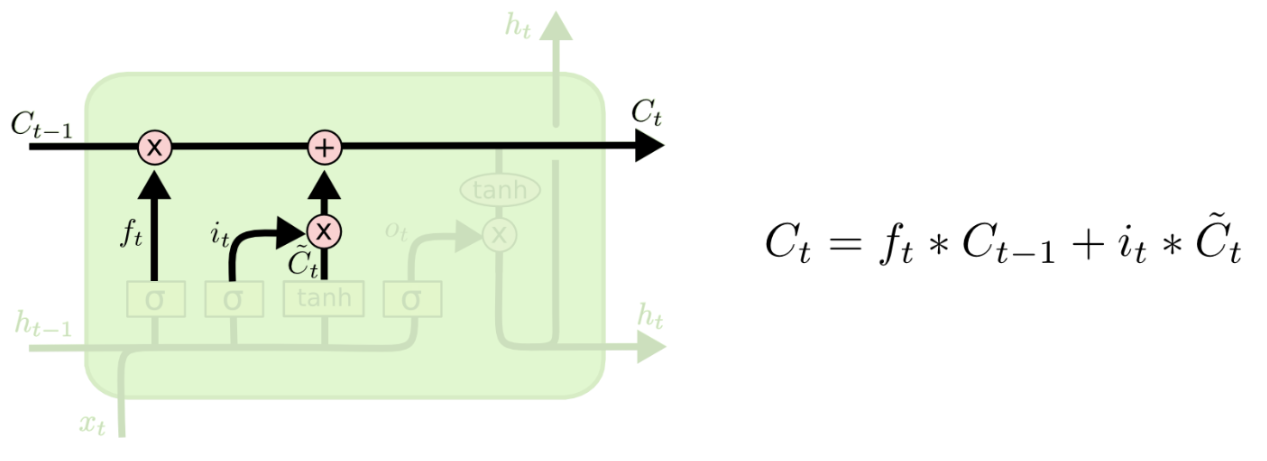
정보의 중요도에 따라 크기가 달라진 C(t)의 값을 tanh에 넣어서 이 값을 다시 -1과 1사이의 값으로 만들어 준 후 o(t)에 곱해 줌으로써 h(t)를 계산합니다.
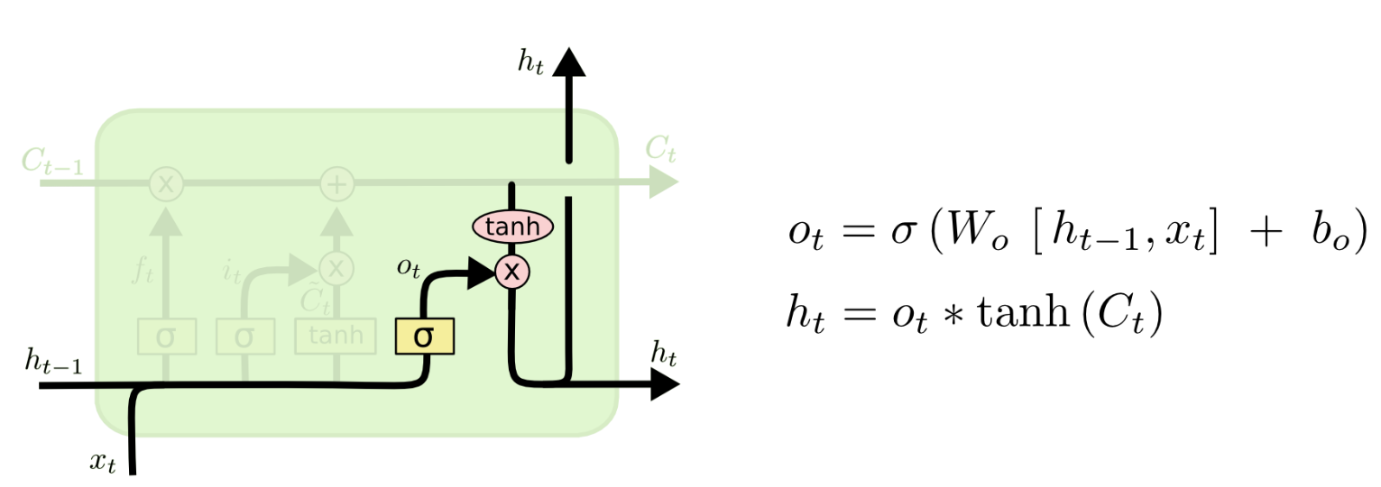
C(t)와 h(t)를 다음 셀에 전달해줍니다.
그래서 이러한 LSTM이 어떤 점에서 바닐라 RNN이 가지는 한계를 극복하게 된걸까요? 그것은 바로 C(t)가 셀에서 tanh함수를 거치지 않기 때문에 중요한 정보가 셀을 거듭하더라도 약해지지 않고 정보를 잘 전달할 수 있다는 것입니다.
GRU (Gated Recurrent Unit)
GRU(Gated Recurrent Unit)는 2014년 뉴욕대학교 조경현 교수님이 집필한 논문에서 제안되었습니다. GRU는 LSTM의 장기 의존성 문제에 대한 해결책을 유지하면서, 은닉 상태를 업데이트하는 계산을 줄였습니다. 다시 말해서, GRU는 성능은 LSTM과 유사하면서 복잡했던 LSTM의 구조를 간단화 시켰습니다.
LSTM에서는 출력, 입력, 삭제 게이트라는 3개의 게이트가 존재했습니다. 반면, GRU에서는 업데이트 게이트와 리셋 게이트 두 가지 게이트만이 존재합니다. GRU는 LSTM보다 학습 속도가 빠르다고 알려져있지만 여러 평가에서 GRU는 LSTM과 비슷한 성능을 보인다고 알려져 있습니다.
데이터 양이 적을 때는, 매개 변수의 양이 적은 GRU가 조금 더 낫고, 데이터 양이 더 많으면 LSTM이 더 낫다고 알려져 있습니다. GRU보다 LSTM에 대한 연구나 사용량이 더 많은데, 이는 LSTM이 더 먼저 나온 구조이기 때문입니다.