딥러닝의 규제를 통한 일반화
1. 모델의 일반화
모델의 일반화란 무엇일까요? 모델이 특정 데이터에만 잘 맞는 것이 아니라 전례가 없는 데이터에 대해서도 높은 정확도를 유지하도록 하는 것을 모델의 일반화라고 합니다. 그러기 위해서는 우선 우리가 해결하고자 하는 문제가 가지고 있는 데이터의 특징 공간을 모델이 충분히 잘 수용할 수 있어야 합니다.
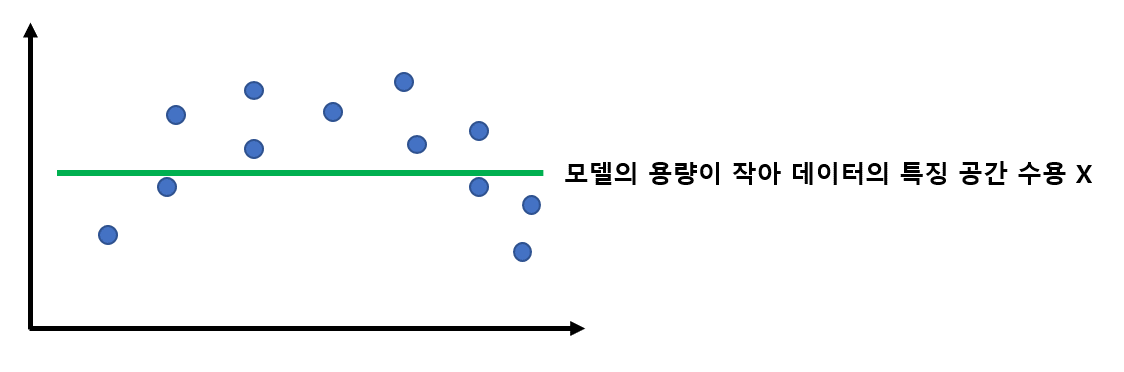
모델의 용량은 데이터를 나타낼 수 있는 모델의 차원이라고 생각합니다. 따라서 모델이 데이터의 특징을 잘 찾아내기 위해서는, 모델의 차원이 데이터의 특징 공간의 차원 보다는 높아야 합니다. 그럼 무조건 모델의 용량이 크면 다 해결되는 걸까요? 그렇지는 않습니다. 왜냐하면 데이터에는 우리가 정말로 원하는 성분 말고도 우리가 원치 않는 노이즈가 함께 존재하는 경우가 대부분이기 때문입니다. 용량이 너무 크면 모델은 노이즈에 대한 잘못된 특징도 수용하기 때문에 성능이 떨어지게 됩니다. 이러한 현상을 모델이 데이터에 과잉적합되었다고 합니다. 따라서 현대 기계 학습은 용량이 충분히 큰 모델을 선택한 후, 선택한 모델이 노이즈에 민감하지 않도록 하기 위해 여러 가지 규제 기법을 적용하는 접근방법을 채택합니다.
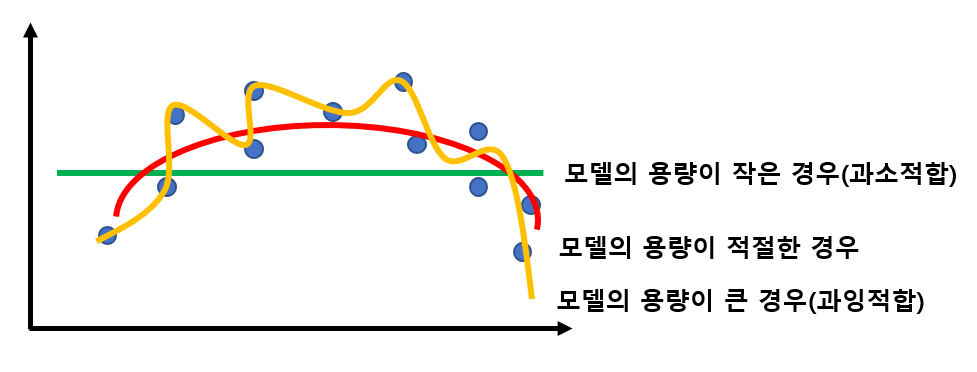
용량이 충분히 큰 모델에 여러 가지 규제 기법을 적용해 일반화 능력을 높일 수 있다.
2. 규제의 필요성과 원리
따라서 우리는 모델이 주어진 문제에 대해 최소한의 역할을 하기 위해 용량을 크게 하는 것이 좋으며(과소 적합 방지), 전례가 없는 데이터에 대해서도 높은 정확도를 가지는 성능이 좋은 모델을 만들기 위해 모델을 잘 일반화 시켜야 합니다(과잉 적합 방지).
그리고 모델을 일반화 시키기 위한 방법을 우리는 규제라고 합니다.
규제의 정의
일반화 오류를 줄이기 위해 학습 알고리즘을 수정하는 모든 방법
3. 규제 기법
현대 기계 학습은 아주 다양한 규제 기법을 사용합니다.
- 데이터를 통해
- Data Augmentation -> Noise injection
- Loss 함수를 통해
- Weight Decay -> L1, L2 규제
- Neural network layer를 통해
- Dropout
- 학습 방식, 추론 방식을 통해
- Early Stopping
- Bagging & Ensemble
1) 데이터 증가(Data Augmentation)
핵심 특징을 간직한 채, noise를 더하여 데이터를 확장하는 방법으로 보통 핵심 특징을 보존하기 위해 휴리스틱한 방법을 사용합니다.
이를 통해 더욱 noise robust한 모델을 얻을 수 있습니다. 규칙을 통해 데이터를 증가시키려고 하면 모델이 그 규칙을 배우게 되기 때문에
규칙이 아닌 Randomness를 통해 데이터를 증가시켜야 합니다.
a) Salt & Pepper Noise
- Adding RGB(255, 255, 255) noise
- Adding RGB(0, 0, 0) noise

b) Rotation, Flipping Shifting

c) Dropping, Exchanging for Text augmentation
- 임의의 단어를 생략한다
- 임의로 특정 단어를 주변 단어와 위치를 바꾼다
d) 새로운 데이터 생성
- Autoencoder, GAN을 통해 데이터를 학습 후 새로운 데이터 생성
2) 가중치 벌칙
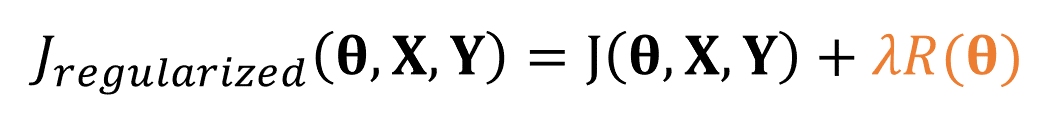
가중치 𝛉가 커지게 되면 R항이 커지게 되고 그러면 손실 함수 J가 증가하게 됩니다. 우리의 학습 알고리즘은 손실 함수가 작아지도록 하므로 R항은 가중치의 크기에 제약을 가하는 역할을 한다고 볼 수 있습니다. 규제 항 R은 가중치를 작은 값으로 유지하므로 모델의 용량을 제한하는 역할을 한다고 볼 수 있습니다. 𝜆는 층마다 다르게 할 수도 있고 같게 할 수도 있습니다.
하지만 실제로 사용하게 되면 성능이 오히려 떨어져 잘 사용하진 않습니다.
L2놈
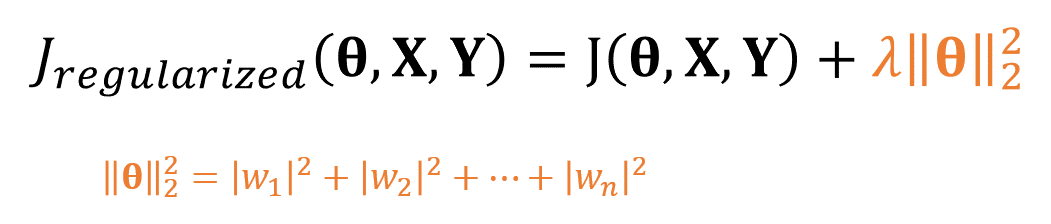
규제 항 R로 가장 널리 쓰이는 것은 L2놈이며 이를 가중치 감쇠 기법이라고 합니다.
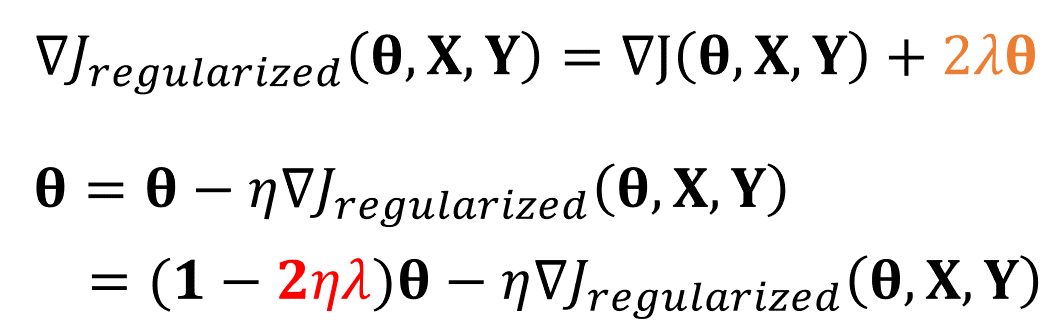
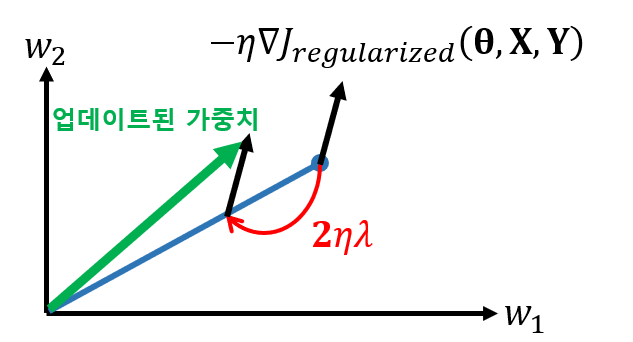
목적 함수가 달라졌으므로, 그래디언트와 가중치 또한 바뀌게 됩니다.
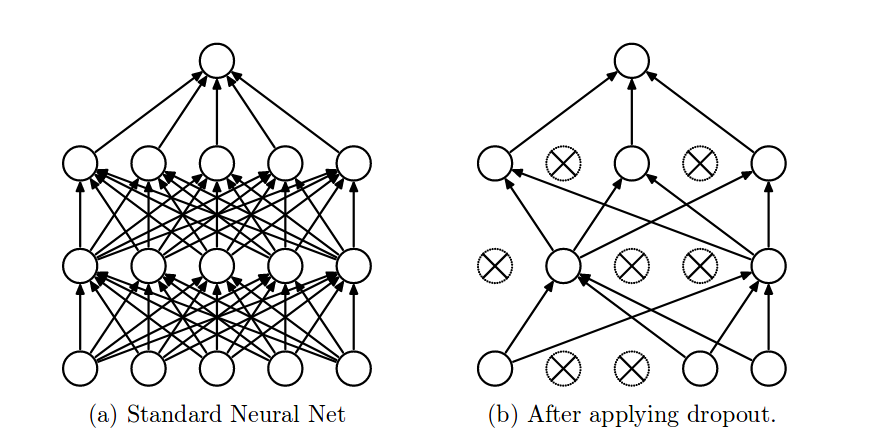
3) 드롭아웃(Dropout)
드롭아웃이란, 입력층과 은닉층의 모든 노드에 대해 일정 확률로 노드를 임의로 제거하는 것입니다. 해당되는 노드의 들어오고 나가는 엣지들을 모두 제거합니다.(0을 출력합니다) 보통 드롭아웃될 확률의 0.1~0.5로 합니다.
여기서 이렇게 하는 것이 과연 어떤 의미가 있는지 궁금해 하시는 분들이 있을 것 같아 예를 한 가지 들어보도록 하겠습니다. 어떤 회사에서 직원들이 아침마다 일정 확률로 회사를 쉰다면 어떻게 될까요? 회사가 이런 식으로 운영된다면 어떠한 업무도 한 사람에게 전적으로 의지할 수 없게 되고, 전문성이 여러 사람에게 나뉘어져 있어야 합니다. 그렇기에 이 회사는 유연성이 훨씬 더 높아질 것입니다. 한 직원이 직장을 떠나도 크게 달라지는 것이 없을 것입니다.
신경망 또한 마찬가지입니다. 노드들은 몇 개의 노드에만 지나치게 의존할 수 없습니다. 모든 노드에 주의를 기울여야 합니다. 그러므로 입력값의 작은 변화에 덜 민감해집니다. 결국 더 안정적인 네트워크가 되어 일반화 성능이 좋아집니다.
테스트시에는 드롭아웃을 사용하지 않는 보통 신경망처럼 전방 계산을 수행하기 때문에 출력이 학습할 떄에 비해 1/p배 더 큽니다. 따라서 W에 p를 곱하여 이를 상쇄시켜 줘야합니다.
일반적으로 (출력층을 제외한) 맨 위의 층부터 세 번째 층까지 있는 노드에만 드롭아웃을 적용합니다. 또한 많은 최신 신경망 구조는 마지막 은닉층 뒤에만 드롭아웃을 사용합니다.

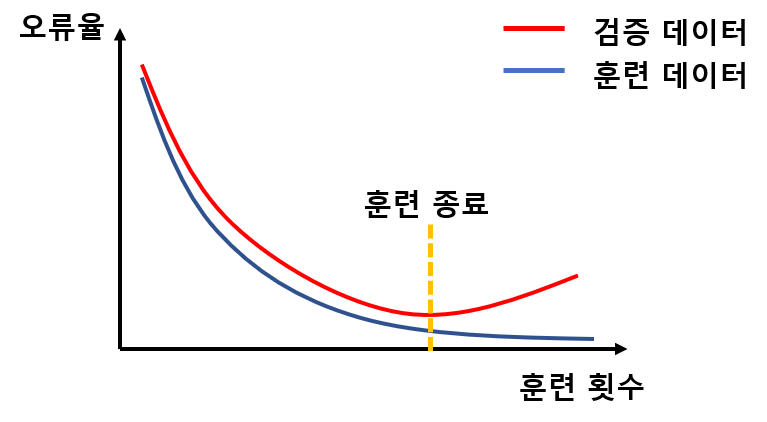
4) 조기 멈춤(Early stopping)
보통 학습을 오래 시킬수록 더 최적점에 접근합니다. 하지만 어떤 시점을 넘어서면 모델이 훈련 데이터에만 너무 최적화가 되어 검증집합에 대해서는 오히려 성능이 떨어지기 시작합니다. 다시 말해, 일반화 능력이 하락하기 시작하는 것입니다. 따라서 일반화 능력이 최고인 지점, 즉 검증집합의 오류가 최저인 지점에서 학습을 멈추는 전략을 조기 멈춤이라고 합니다.