
아스키(ASCII) 코드
초기에 문자를 표현하던 대표적인 방식은 ASCII 인코딩 방식으로, 1바이트에 모든 문자를 표현했습니다. 게다가 1비트는 체크섬으로 제외하여 7비트, 즉 128개의 글자로 문자를 표현했습니다. 그러다 보니 한글이나 한자 같은 문자는 2개 이상의 특수 문자를 합쳐서 표현하는 비정상적인 방법을 사용했기에, 경우에 따라서는 깨지거나 제대로 표현되지 않는 경우가 잦았습니다.
유니코드 (Unicode)
이런 문제를 해결하기 위해 2~4바이트의 공간에 여유 있게 문자를 할당하고자 등장한 방식이 바로 유니코드입니다. 그러나 유니코드 자체는 1바이트로 표현이 가능한 영문자도 2바이트 이상의 공간을 사용했기 때문에 이를 그대로 사용하기에는 메모리 낭비가 심했습니다.
(유니코드도 일종의 인코딩(문자나 기호를 컴퓨터가 이해할 수 있는 신호로 바꾸는 것)이지만 이를 효율적으로 사용하기 위해 source는 유니코드이지만 좀 더 효율적인 방식으로 개발된 인코딩 방식이 UTF-8인코딩 (뇌피셜))
UTF-8 (Universal Coded Character Set + Transformation Format – 8-bit)
이를 해결해주는 효율적인 인코딩 방식이 있는데 이것이 바로 UTF-8 인코딩입니다. UTF-8은 가변 길이 문자 인코딩 방식으로 유니코드 한 문자를 나타내기 위해 1바이트에서 4바이트까지를 사용합니다.
예를 들어, 만약 모든 문자를 4바이트로 표현했다면 Python이라는 영문 문자열은 다음과 같이 24바이트의 메모리를 차지하게 될 것입니다.

그런데 이러한 방법은 확실히 문제가 있습니다. 왜냐하면 영문자는 ASCII 코드로도 충분히 표현이 가능해 각 문자당 1바이트로 충분하기 때문입니다. 이런 문제를 해결하기 위한 여러 가지 가변 인코딩 방식이 등장했고 그 중 가장 유명한 방식이 바로 UTF-8입니다. 그렇다면 UTF-8은 어떤 방식으로 유니코드를 인코딩할까요?
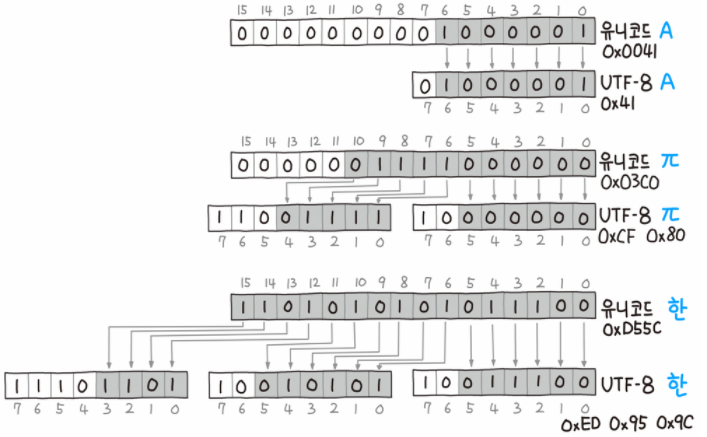
핵심은 유니코드 값에 따라 가변적으로 바이트를 결정함으로써 불필요한 공간 낭비를 줄이겠다는 것입니다. 그런데 컴퓨터가 sequence of bytes를 입력으로 받았을 때 어디까지를 하나의 문자로 봐야하는지 어떻게 알 수 있을까요? 이를 위해 UTF-8에서는 다음과 같은 이진 포맷을 사용합니다.

이렇게 하면 컴퓨터는 문자 바이트의 길이를 인식할 수 있습니다.
참고로 영문, 숫자를 포함한 기존의 ASCII 문자들은 그대로 1바이트로 표현하며, 𝜋는 2바이트, ‘한’과 같은 한글은 3바이트를 차지합니다.
(출처: 파이썬 알고리즘 인터뷰 (도서))
파이썬은 유니코드? UTF-8?
파이썬은 3버전부터 유니코드로 모든 문자열을 표현하지만 UTF-8인코딩을 사용하지는 않습니다. 왜 그럴까요?
그 이유는 인덱스를 통해 개별 문자에 접근하기가 어렵기 때문입니다.
파이썬에서는 문자열 슬라이싱을 비롯해 원하는 문자에 인덱스로 접근하는 다양한 방식을 제공하는데, 만약 문자열을 UTF-8로 인코딩한다면 각 문자마다 바이트 길이가 달라지게 되어, 전체 문자열을 스캔하지 않는 한 원하는 인덱스에 빠르게 접근할 수 없습니다. 따라서 파이썬에서는 고정 길이 인코딩 방식이 필요하여, 이를 문자열 단위로 다른 고정 길이 인코딩 방식을 적용해 해결합니다.
만약 모든 문자열이 ASCII 범위 내에 있다면 Latin-1 인코딩(고정 1바이트 인코딩), 이 외의 대부분 문자열은 UCS-2 인코딩(고정 2바이트 인코딩), 특수 기호, 이모티콘, 희귀 언어는 UCS-4 인코딩(고정 4바이트 인코딩)을 사용합니다.
이처럼 각 문자열에 포함된 문자 범위에 따라 서로 다른 고정 인코딩 방식을 택함으로써, 파이썬은 슬라이싱, 인덱스의 빠른 접근을 가능하게 합니다.