
Hugging face: Introduction
Huggingface에 관한 포스트는 Huggingface 공식 홈페이지를 참고하여 작성하였으며 그 중에서도 Huggingface를 사용하는 방법에 관해 친절하게 설명해 놓은 글(Huggingface course)이 있어 이것을 바탕으로 작성하였습니다.
Huggingface는 자연어 처리(NLP)를 위한 생태계(Ecosystem)로 대표적으로 🤗Transformers, 🤗Datasets, 🤗Tokenizers과 같은 라이브러리를 제공합니다.
1. 코스 일정
- Chapters 1-4에서는 🤗
Transformers library에 관한 핵심 개념들을 설명합니다. 이 과정을 공부하고 나면, Transformer모델이 어떻게 동작하고, Hugging Face Hub로 부터 모델을 어떻게 가져와서 사용하는지, 각각의 task에 맞게 어떻게 fine-tuning하는지에 대해서 알게 됩니다. - Chapters 5-8에서는 🤗
Datasets과🤗Tokenizers라이브러리에 대해 공부한 후, 각각의 NLP task들에 대해 조금 더 깊이 공부합니다. - Chapters 9-12에서는 메모리 효율, 긴 문장에 대한 문제 해결과 같은 조금 더 특화된 모델의 구조에 대해 공부하며 훈련 속도를 높이는 방법에 대해 공부합니다.
(현 시점에서는 Introduction에 해당하는 Chap 1-4까지 밖에 포스트 업로드가 안되어 있어서 Introduction만 다룰 예정입니다)
2. NLP란 무엇인가
NLP is a field of linguistics and machine learning focused on
understanding everything related to human language. The aim of NLP tasks is not only to understand single words individually, but to be able to understand the context of those words.
Typical tasks about NLP
Huggingface에서는 NLP의 task를 크게 다음과 같이 분류하고 있습니다.

그리고 각 모델별로 다음과 같은 task를 지원합니다.
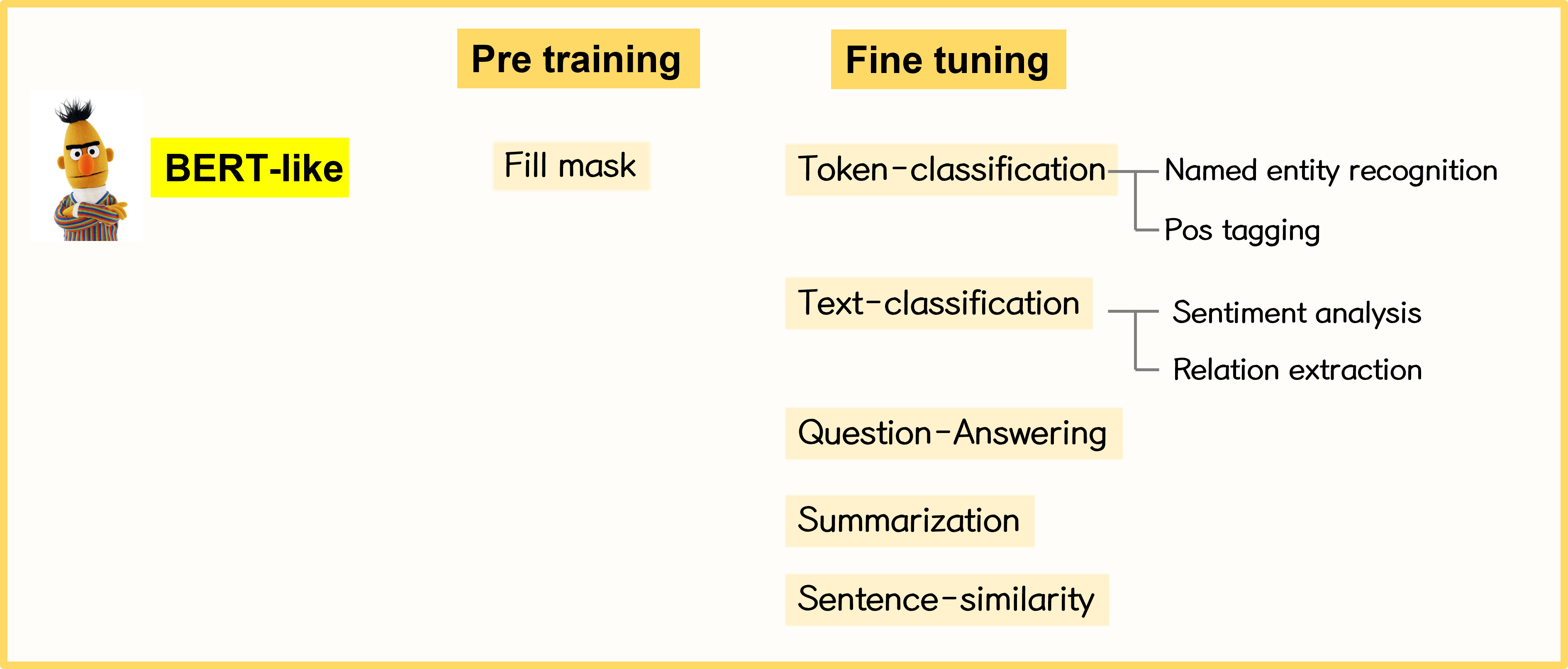
자세한 내용은 뒤에서 다루도록 하겠습니다.
3. 어떤 이유에서 challenging한가
Computers don’t process information in the same way as humans. For example, when we read the sentence “I am hungry,” we can easily understand its meaning. Similarly, given two sentences such as “I am hungry” and “I am sad,” we’re able to easily determine how similar they are. For machine learning (ML) models, such tasks are more difficult.
The text needs to be processed in a way that enables the model to learn from it. And because language is complex, we need to think carefully about how this processing must be done. There has been a lot of research done on how to represent text, and we will look at some methods in the next chapter.
- 컴퓨터는 사람과 같은 방식으로 언어를 이해할 수 없다.
- 그래서 컴퓨터가 사람의 언어를 처리하기 위해서는 그에 맞는 방법을 사용해야 한다.