
Hugging face: Tokenizers
Huggingface에 관한 포스트는 Huggingface 공식 홈페이지를 참고하여 작성하였으며 그 중에서도 Huggingface를 사용하는 방법에 관해 친절하게 설명해 놓은 글(Huggingface course)이 있어 이것을 바탕으로 작성하였습니다.
이번 포스트에서는 Tokenizer의 종류와 사용하는 방법에 대해 조금 더 자세히 알아보겠습니다.🤗
1. Word-based
In NLP tasks, the data that is generally processed is raw text. Here’s an example of such text:
Jim Henson was a puppeteer
However, models can only process numbers, so we need to find a way to convert the raw text to numbers. That’s what the tokenizers do, and there are a lot of ways to go about this. The goal is to find the most meaningful representation — that is, the one that makes the most sense to the model — and, if possible, the smallest representation.
Let’s take a look at some examples of tokenization algorithms, and try to answer some of the questions you may have about tokenization.
The first type of tokenizer that comes to mind is word-based. It’s generally very easy to set up and use with only a few rules. For example, in the image below, the goal is to split the raw text into words and find a numerical representation for each of them:
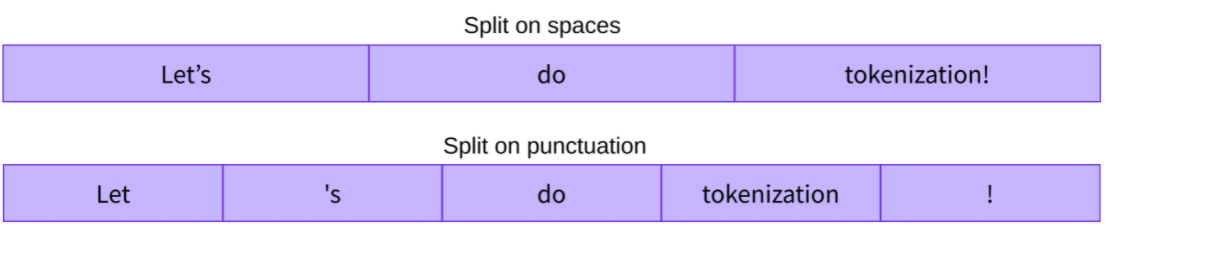
There are different ways to split the text. For example, we could could use whitespace to tokenize the text into words by applying Python’s split function:
tokenized_text = "Jim Henson was a puppeteer".split()
print(tokenized_text)
---------------------------------------------------
['Jim', 'Henson', 'was', 'a', 'puppeteer']
If we want to completely cover a language with a word-based tokenizer, we’ll need to have an identifier for each word in the language, which will generate a huge amount of tokens. For example, there are over 500,000 words in the English language, so to build a map from each word to an input ID we’d need to keep track of that many IDs. Furthermore, words like “dog” are represented differently from words like “dogs”, and the model will initially have no way of knowing that “dog” and “dogs” are similar: it will identify the two words as unrelated.
Finally, we need a custom token to represent words that are not in our vocabulary. This is known as the “unknown” token, often represented as ”\[UNK]”. It’s generally a bad sign if you see that the tokenizer is producing a lot of these tokens, as it wasn’t able to retrieve a sensible representation of a word and you’re losing information along the way. The goal when crafting the vocabulary is to do it in such a way that the tokenizer tokenizes as few words as possible into the unknown token.
One way to reduce the amount of unknown tokens is to go one level deeper, using a character-based tokenizer.
2. Character-based
Character-based tokenizers split the text into characters, rather than words. This has two primary benefits:
- The vocabulary is much smaller.
- There are much fewer out-of-vocabulary (unknown) tokens, since every word can be built from characters.

This approach isn’t perfect either. Since the representation is now based on characters rather than words, one could argue that, intuitively, it’s less meaningful: each character doesn’t mean a lot on its own
Another thing to consider is that we’ll end up with a very large amount of tokens to be processed by our model: whereas a word would only be a single token with a word-based tokenizer, it can easily turn into 10 or more tokens when converted into characters.
To get the best of both worlds, we can use a third technique that combines the two approaches: subword tokenization.
3. Subword tokenization
Subword tokenization algorithms rely on the principle that frequently used words should not be split into smaller subwords, but rare words should be decomposed into meaningful subwords.
For instance, “annoyingly” might be considered a rare word and could be decomposed into “annoying” and “ly”. These are both likely to appear more frequently as standalone subwords, while at the same time the meaning of “annoyingly” is kept by the composite meaning of “annoying” and “ly”.
This approach is especially useful in agglutinative languages(교착어: 교착어란 하나의 낱말(엄밀히는 하나의 어절)이 하나의 어근(root)과 각각 단일한 기능을 가지는 하나 이상의 접사(affix)로 이루어져 있는 언어를 말한다. 어간과 접사 사이의 경계를 분명히 설정할 수 있고, 하나의 접사가 대체로 하나의 기능만을 가지고 있으면 그 언어를 교착어라고 한다.) such as Korean, where you can form (almost) arbitrarily long complex words by stringing together subwords.
4. And more!
- Byte-level BPE, as used in GPT-2
- WordPiece, as used in BERT
- SentencePiece or Unigram, as used in several multilingual models
5. Loading and Saving
Loading and saving tokenizers is as simple as it is with models. Actually, it’s based on the same two methods: from_pretrained and save_pretrained. These methods will load or save the algorithm used by the tokenizer as well as its vocabulary.
Loading the BERT tokenizer trained with the same checkpoint as BERT is done the same way as loading the model, except we use the BertTokenizer class:
from transformers import BertTokenizer, AutoTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
# tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenizer("Using a Transformer network is simple")
-----------------------------------------------------------------
{'input_ids': [101, 7993, 170, 11303, 1200, 2443, 1110, 3014, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
tokenizer.save_pretrained("directory_on_my_computer")
We’ll talk more about token_type_ids in Chapter 3, and we’ll explain the attention_mask key a little later. First, let’s see how the input_ids are generated. To do this, we’ll need to look at the intermediate methods of the tokenizer.
6. Encoding
Translating text to numbers is known as encoding. As we’ve seen, the first step is to split the text into words (or parts of words, punctuation symbols, etc.), usually called tokens. There are multiple rules that can govern that process, which is why we need to instantiate the tokenizer using the name of the model, to make sure we use the same rules that were used when the model was pretrained.
The second step is to convert those tokens into numbers, so we can build a tensor out of them and feed them to the model. To do this, the tokenizer has a vocabulary, which is the part we download when we instantiate it with the from_pretrained method. Again, we need to use the same vocabulary used when the model was pretrained.
1) Tokenize
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
sequence = "Using a Transformer network is simple"
tokens = tokenizer.tokenize(sequence)
print(tokens)
-----------------------------------------------------------
['Using', 'a', 'transform', '##er', 'network', 'is', 'simple']
2) From tokens to input IDs
ids = tokenizer.convert_tokens_to_ids(tokens)
print(ids)
---------------------------------------------
[7993, 170, 11303, 1200, 2443, 1110, 3014]
모델이 요구하는 조건에 맞춰서 special token을 달아주는 방법도 있습니다.
ids = tokenizer.encode(sequence)
print(ids)
------------------------------------------------------
[101, 7993, 170, 13809, 23763, 2443, 1110, 3014, 102]
tokens = tokenizer.decode(ids)
------------------------------------------------------
[CLS] Using a Transformer network is simple [SEP]
7. Decoding
decoded_string = tokenizer.decode([7993, 170, 11303, 1200, 2443, 1110, 3014])
print(decoded_string)
------------------------------------------
'Using a Transformer network is simple'