GOOD EXPRESSION related to Attention
seq2seq 모델은 인코더에서 입력 시퀀스를 context vector라는 하나의 고정된 크기의 벡터 표현으로 압축하고, 디코더는 이 context vector에 기반해 출력 시퀀스를 만들어냈습니다.
하지만 마지막 context vector만을 이용해 출력 시퀀스를 만들어 내는 것으로는 좋은 성능을 갖는 machine translation 모델을 만들기 힘듭니다. (정보 손실, 기울기 소실 문제)
그래서 이를 위한 대안으로 Attention이 등장하게 되었습니다.
Attention의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점마다, 인코더에서의 전체 입력 문장을 참고한다는 점입니다. 여기서 중요한 점은 전체 임베딩 벡터를 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야 할 단어와 연관이 있는 부분을 집중적으로(attention) 본다는 점입니다.
모델이 단어 각각을 번역하는 과정에서, 목표 문장의 단어를 생성할 때마다 원 문장에서 가장 관련된 정보들에 대한 검색을 실시합니다.
해당 모델은 디코딩할 때 디코더의 hidden state와 어텐션을 통해 인코더로부터 얻은 벡터 중 적절한 부분집합을 선택하여 사용합니다.
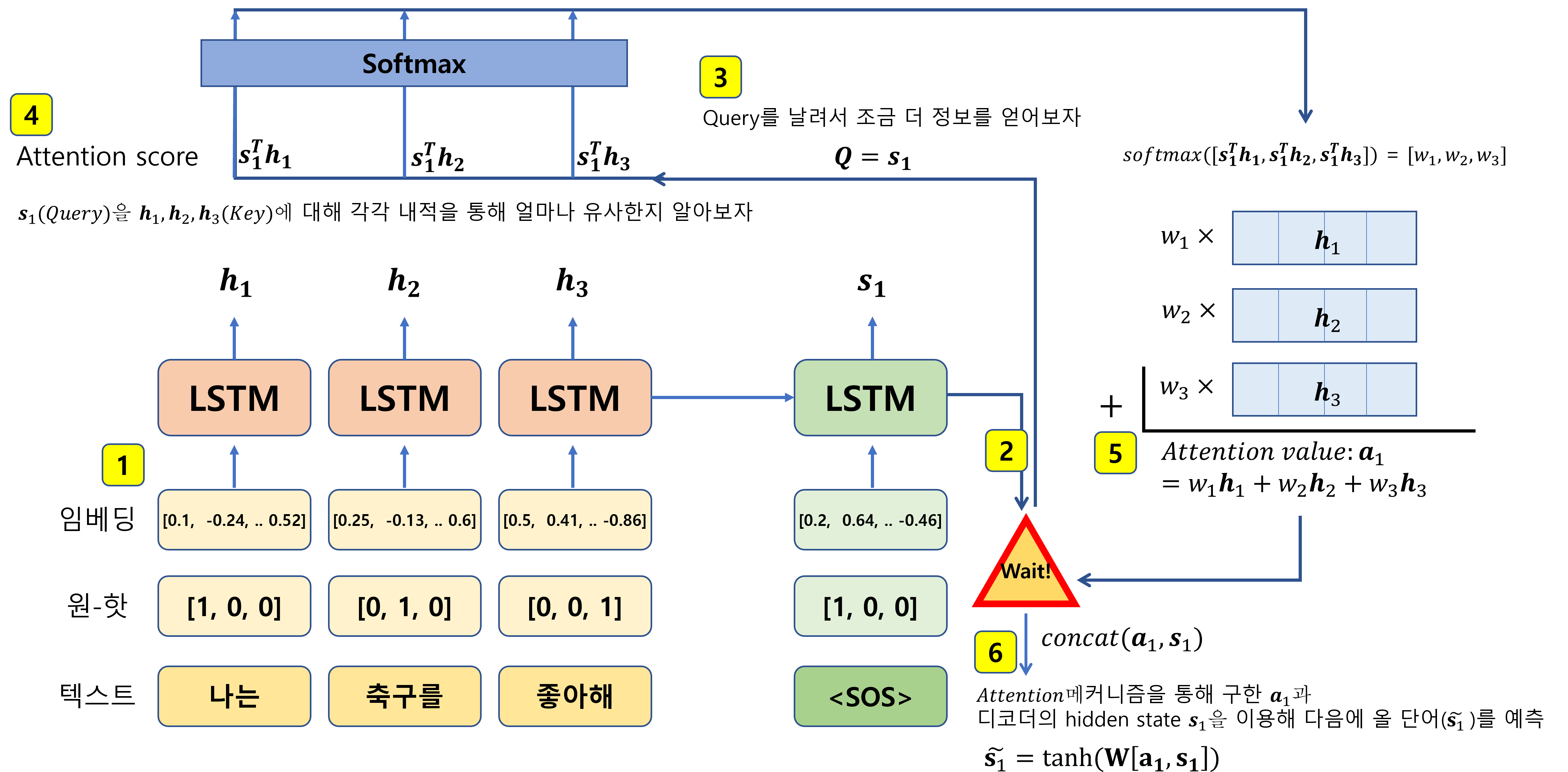
Attention value 계산: Query, Key, Value
Q: 특정 시점의 디코더 셀에서의 hidden state (내가 찾기 위해 던진 질문)
K: 입력으로 이용된 모든 임베딩 벡터의 인코더에서의 hidden states (질문과의 비교대상)
V: 입력으로 이용된 모든 임베딩 벡터의 인코더에서의 hidden states (Q, K로 구해진 유사도에 관한 가중치가 가중합 되는 대상)
예측해야 하는 시점에 Q를 인코더에 보냅니다. 그럼 인코더에서는 이 Q(Q: Query vector가 인코더에서 Query를 위한 가중치 매트릭스와 곱해진 값)를 바탕으로 각각의 K값들과 (K: Key가 Key를 위한 매트릭스와 곱해진 값) dot product를 수행하고 그 값을 소프트맥스 함수에 넣으면 각 V에 줘야할 가중치(Attention score)를 얻게 됩니다. 이 결과를 Attention value라고 합니다.
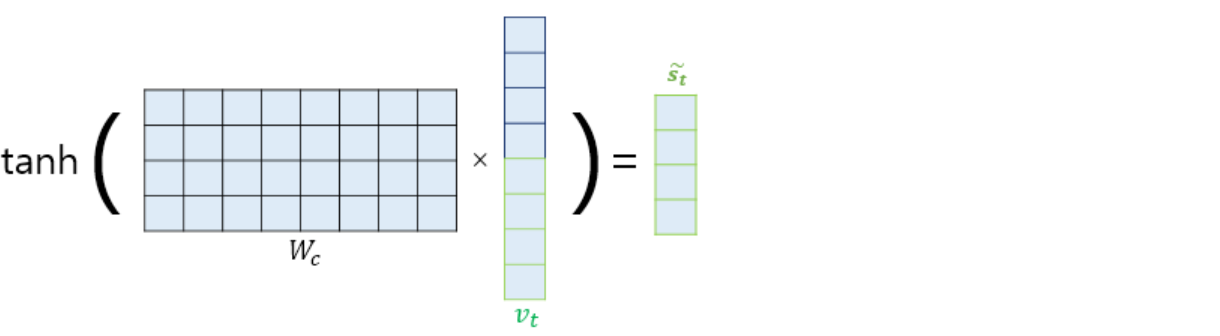
참고로 s_t는 3개의 입력을 이용해 만들어진다 -> 1. 해당 셀의 입력(x_t), 2. 이전 셀의 hidden state(s_(t-1)), 3. 어텐션
Attention에서 유의해야 할 점
Attention은 최근 딥러닝에서 가장 주목받고 있는 메커니즘 중에 하나입니다. 여기서 주의할 점은 Attention을 사용하고 있는 모든 모델들이 위와 똑같은 방법으로 Attention을 사용하고 있지는 않다는 점입니다. 나중에 배울 Vanilla Transformer에만 해도 Self-Attention, Masked Decoder Self-Attention, Encoder-Decoder Attention과 같이 여러 Attention 메커니즘이 이용됩니다. 그래서 여기서는 그냥 포인트만 잡고 뒤에서 배울 모델들에 적용되는 Attention은 그때 그때 이해를 하면 좋을 것 같습니다.
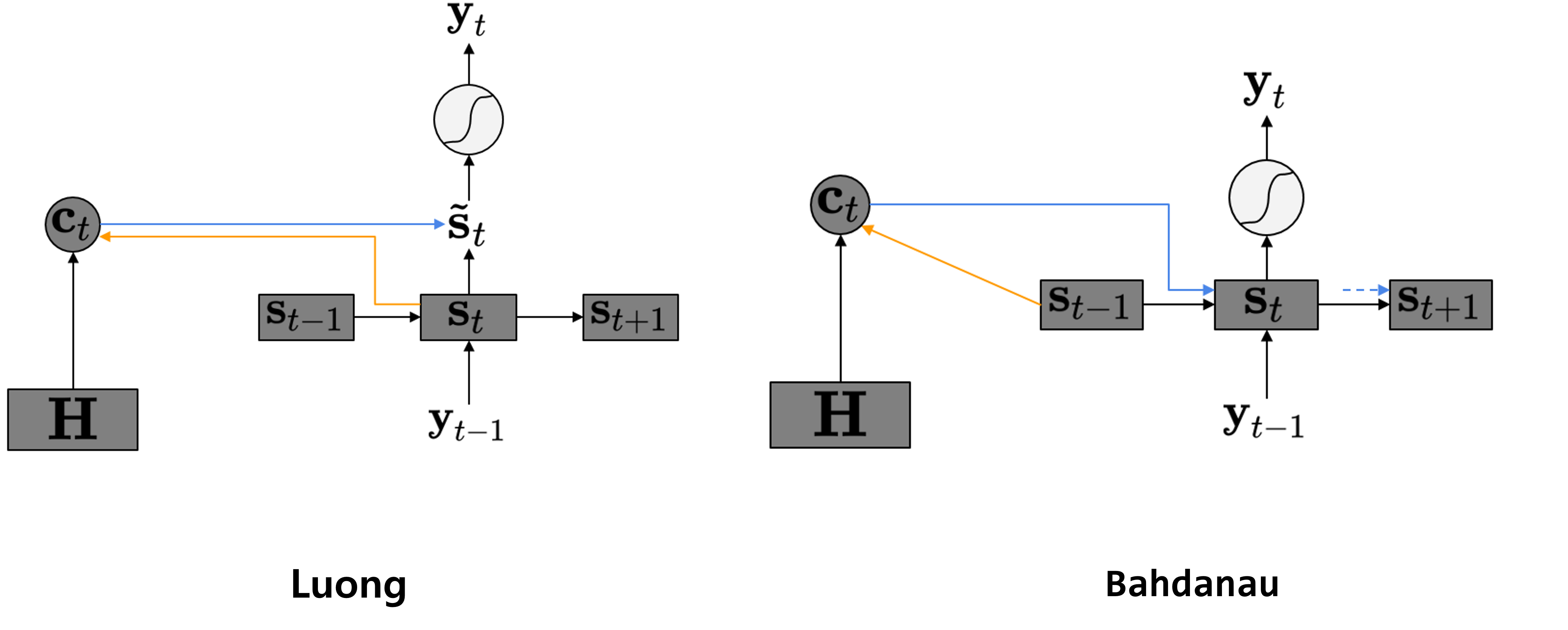
Bahdanau Attention
Bahdanau Attention이 Luong Attention과 가장 큰 다른점은 Bahdanau Attention의 Query는 s_t가 아니라, s_(t-1)이라는 점이다.