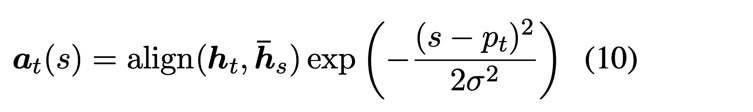Effective Approaches to Attention-based Neural Machine Translation
논문: 링크
1. 등장배경: Attention
이 논문의 저자인 Minh-Thang Luong이 제안한 모델의 컨셉은 간단하다. 입력 문장을 계속 읽다가 <eos>기호가 나타나면 그 때부터 target word를 하나씩 예측하기 시작한다. 또한 최근 많은 인기를 얻고 있으며 서로 다른 modality를 alignment하는 task에서 좋은 성능을 보이는 어텐션(attention)을 Machine Translation에 적용하였다. 어텐션 메커니즘은 입력 문장의 특정 부분에 집중함으로써 Neural Machine Translation 관련 task에서 성능을 많이 향상시켰다. 일반적인 Neural Machine Translation모델은 다음과 같은 recurrent모델을 Encoder, Decoder에 사용한 Seq2Seq 모델을 사용하였다.
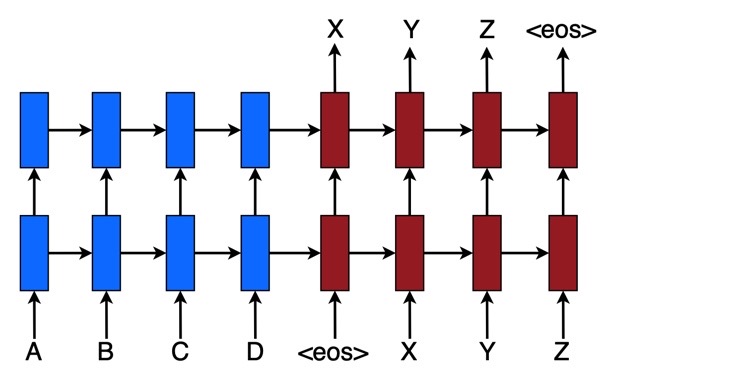
또한 이 논문에서는 두 가지의 attention 기반의 모델을 제안한다. 하나는 모든 입력 문장을 attention 계산에 이용하는 global approach와 입력 문장의 특정 부분만을 attention 계산에 이용하는 local approach가 있다. 이 논문에서 제공한 결과에 따르면 global보다는 전체 입력 문장 중 prediction할 때 더 중요한 부분만을 attention 계산에 이용하는 local approach가 성능이 더 좋은 것으로 나왔다.
2. Neural Machine Translation
NMT는 입력 문장을 표현하는 Encoder와 Target words를 생성하는 Decoder로 이루어져 있으며, 다음과 같은 조건부 확률을 최대로 하도록 한다.
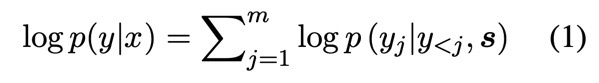
여기서 $p(y_j|y_{<j}, \textbf{s})$는 다음과 같은 식으로 모델을 나타낼 수 있습니다.
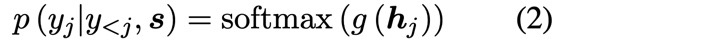
여기서 $g$는 output size를 vocabulary-sized vector로 만들어주는 Linear layer이며 $\textbf{h}_j$는 RNN의 hidden unit입니다. 그리고 $\textbf{h}_j$는 다음의 식으로 구해집니다.

여기서 $f$는 LSTM, GRU와 같은 RNN계열의 모델입니다.
그동안 발표되었던 Kalchbrenner and Blunsom, 2013; Sutskever et al., 2014; Cho et al., 2014; Luong et al., 2015 논문들에서는 입력 문장을 context vector로 나타낸 $\textbf{s}$가 Decoder의 hidden state를 initalize할 때만 한 번 사용되었으나 여기서는 $\textbf{s}$가 입력 문장의 set of hidden states를 나타내며 전체 번역 과정에서 사용됩니다.
3. Attention-based Models
Attention 기반의 모델이 앞에서 설명한 NMT와 다른 점은 단지 context vector $\textbf{c}_t$를 어떻게 유도했고, 언제 사용했는가입니다. 일단 context vector가 구해지고 나면 그 이후의 과정은 앞의 NMT모델과 비슷합니다. 앞의 NMT 모델들은 이전 time_step의 hidden state인 $\textbf{h}_{t-1}$ (Encoder가 앞서 만들어 놓은 context vector 또는 Decoder의 previous hidden_state)와 $\textbf{y}_{t-1}$(또는 $\hat{\textbf{y}}_{t-1}$)를 concatenate한 후 적절한 변환을 통해 $\hat{\textbf{y}_t}$를 구했습니다.
Attention-based model은 이전 time_step의 hidden state를 이용해 $\textbf{h}_t$를 구하고 이를 attention mechanism을 이용하여 context vector를 구합니다. 그리고 concatenate과 weight matrix, tanh layer를 지나 $\tilde{\textbf{h}}_t$를 구하고 Linear layer를 통과시킴으로써 해당 time step의 $\hat{\textbf{y}_t}$를 구합니다.
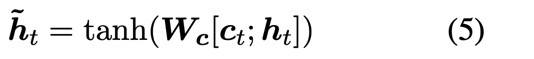
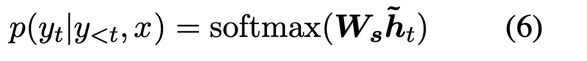
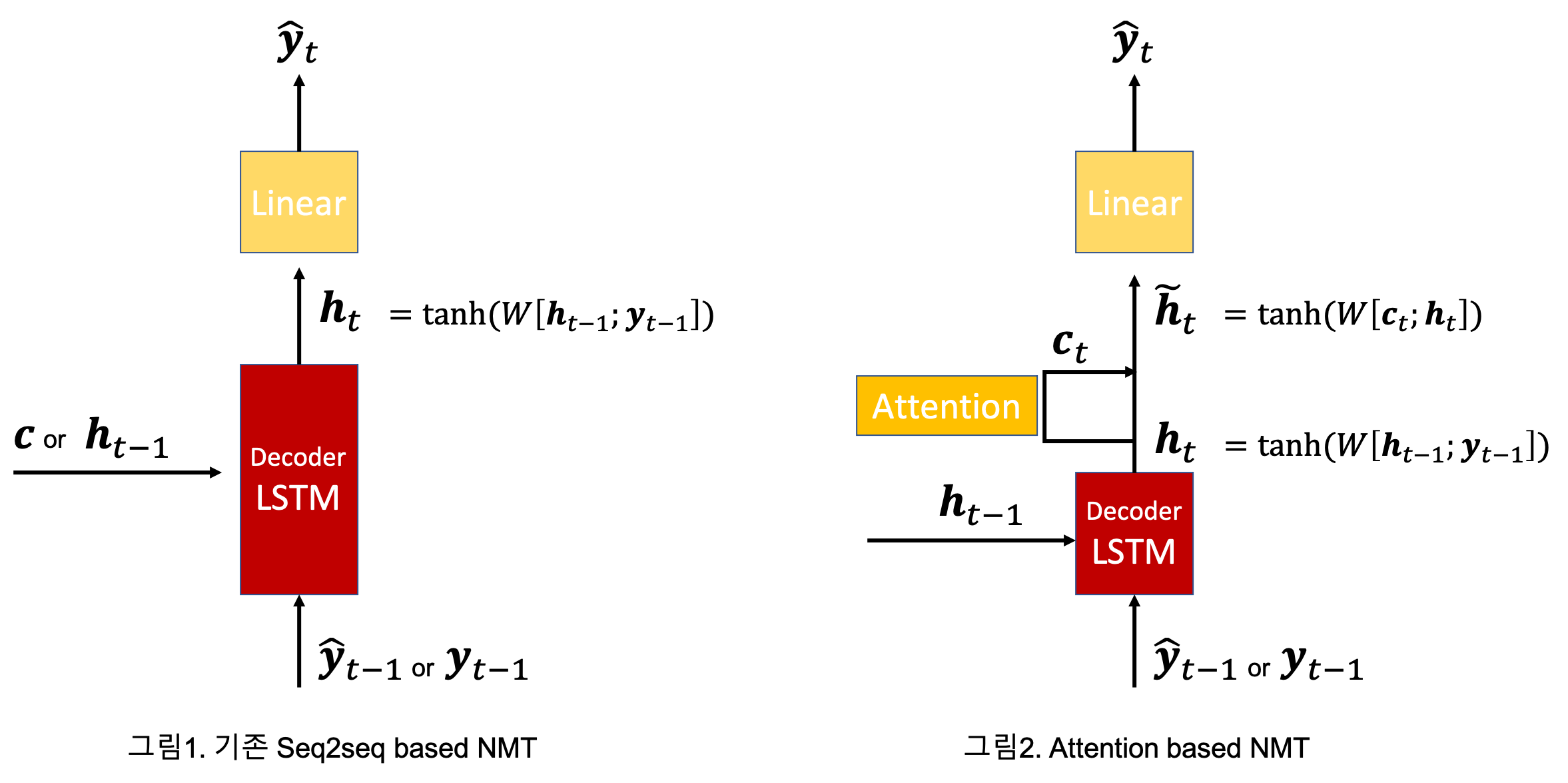
4. Attention을 이용한 context vector
앞서 attention mechanism을 이용하여 context vector를 매 time step마다 생성함으로써 더 나은 성능을 보였다고 설명했다. 지금부터는 attention mechanism을 이용해 context vector를 실제로 어떻게 구하는지 알아보겠다. attention mechanism은 크게 Global과 Local 두 가지 방법이 있다.
1) Global attention
Global attention의 아이디어는 Encoder에서 생성된 모든 hidden state를 고려하여 매 time step마다 context vector를 만들자는 것이다. 이 논문에서 context vector를 생성하는 과정은 다음과 같다.
$\textbf{h}_t$ -> $score(\textbf{h}_t, \bar{\textbf{h}}_t)$ -> $\textbf{a}_t$ -> $\textbf{c}_t$ -> $\hat{\textbf{h}}_t$
$score(\textbf{h}_t, \bar{\textbf{h}}_t)$를 계산하는 방법은 크게 세 가지가 있다. 차이는 가중치를 두고 학습을 시킬 것인지 아닌지의 정도이다
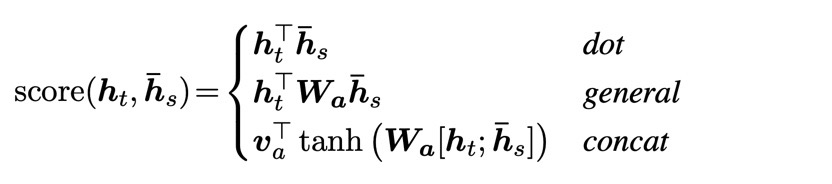
score를 구하고 나면 softmax함수를 취하여 weight의 합을 1로 만든다.
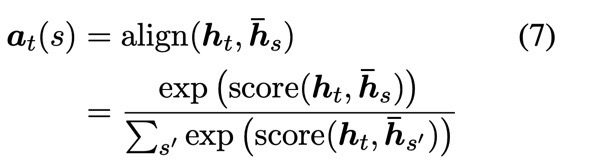
다음과 같이 구해진 $\textbf{a}_t$의 각 성분을 $\bar{\textbf{h}}_s$에 가중합 하게되면 context vector $\textbf{c}_t$가 구해진다.
전체 과정을 그림으로 나타내면 다음과 같다.
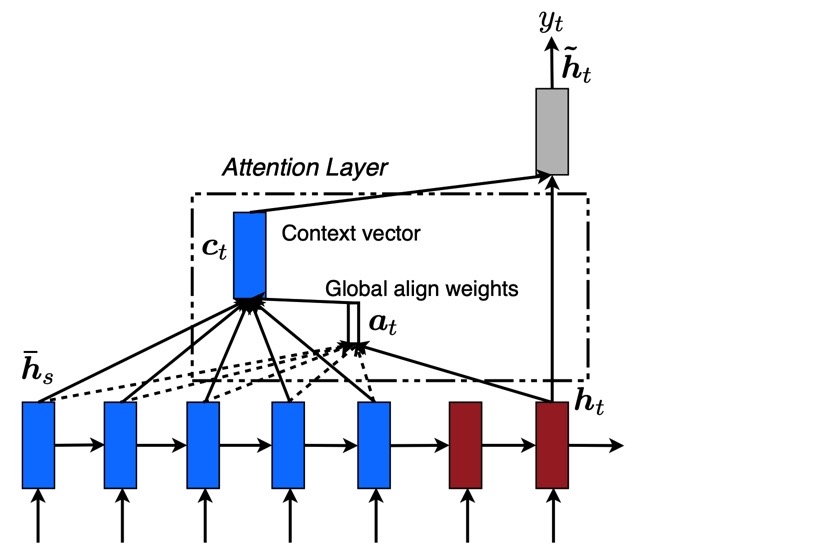
2) Local attention
Global attention은 각각의 target word를 예측할 때마다 모든 source word를 고려해야한다는 것이다.
Local attention 또한 위의 과정과 유사하나 attention을 Encoder의 전체 hidden state가 아닌 특정 시점을 기준으로 windowing하여 특정 부분의 hidden_state만 attention과정에 이용한다는 것이다. 이것은 soft attention과 hard attention간의 trade-off로부터 영감을 받은 것으로, 이러한 접근법은 sotf attention과 비교하여 계산 비용을 줄여주고 hard attention과 비교했을 때는 train과정을 간단하게(hard attention은 non-differentiable) 만든다. 참고로 soft attention은 global attention과 같은 접근법이며, hard attention은 windowing size를 1로 고정하는 것과 같다.
Local attention의 window size를 $D$라고 하면, 선택되는 hidden state의 범위는 [$p_t$-$D$, $p_t$+$D$]이다. $D$는 empirically하게 결정된다. 그러면 여기서 $p_t$는 어떻게 결정될까? $p_t$를 결정하는 방법에는 두 가지가 있다. 하나는 $local-m$으로 source and target sequences가 monotonically하게 align되었다고 가정하고 $p_t$ = $t$로 두는 것이며, 다른 하나는 $local-p$로 학습을 통해 $p_t$를 결정하는 것으로 다음의 식을 이용한다. 여기서 $S$는 source sentence의 길이이고, $\textbf{v}_p$와 $\textbf{W}_p$는 학습시킬 parameter이다. $S$에 sigmoid의 출력값(0~1)을 곱함으로써 source sentence에서 하나의 위치를 얻을 수 있다.
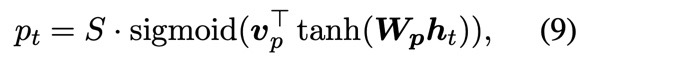
또는 앞에서 구한 global attention에서 구한 $\textbf{a}_t$에 평균이 $p_t$이고 표준편차가 $D$/2인 가우시안 분포를 곱해줌으로써 $\textbf{a}_t$를 구할 수도 있다.