
Sequence to Sequence Learning with Neural Networks
논문: 링크
1. 등장배경: Mapping sequences to sequences
데이터의 순서 정보가 중요한 task의 경우(예를 들어, 언어와 관련된 task), sequence간의 mapping이 가능해야합니다. 기존의 Deep neural network(DNN)는 labeling된 훈련 데이터 셋을 이용한 학습에서 훌륭한 성능을 보여줬습니다. 하지만 sequences to sequences와 관련한 task에서는 그렇지 못합니다. DNN은 입력과 타겟의 shape이 고정되어 있는 경우에 대해서만 적용이 가능합니다. 그 이유는 DNN은 보통 Linear layer를 통해 모델을 깊게 구성하는데 Linear layer가 가지고 있는 가중치 파라미터의 shape은 고정되어 있기 때문에 입력과 타겟의 shape이 바뀌면 안됩니다.
입력의 길이가 고정되어 있지 않은 경우에 발생할 수 있는 문제를 해결해주는 모델이 바로 RNN계열의 모델입니다. RNN계열의 모델은 time step마다 들어오는 입력의 shape만 일정하게 해주면 time step은 그때마다 다르게 할 수 있습니다. 그저 time step만큼 모델을 recurrent해주기만 하면 됩니다. 이러한 장점 덕분에 RNN계열의 모델은 sequence간의 mapping을 가능하게 해줍니다. RNN계열의 모델에는 대표적으로 Vanilla RNN, LSTM, GRU가 있습니다.
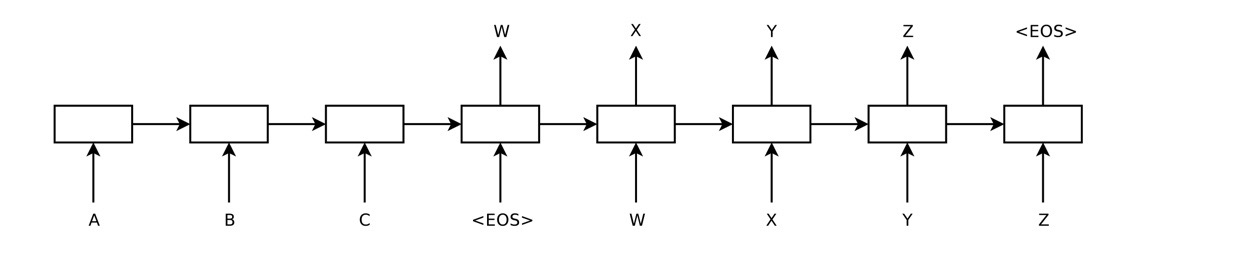
2. 모델의 구조: Encoder and Decoder
단어의 수, 어순이 일치하는 언어라면 RNN계열 하나의 모델만을 이용해서 Mapping Word/Sequence to Word 방법으로 task를 해결할 수도 있지만, 단어의 수도 다르고, 어순도 다른 non-monotonic한 관계의 언어에서는 RNN계열 모델 두 개(Encoder, Decoder)를 사용한 Sequence to Sequence모델이 필요하다. 두 개의 모델을 사용하면 무시할 수 있는 수준의 계산 복잡도로 서로 다른 언어 쌍을 이용한 학습을 자연스럽게 만들어줍니다[1]
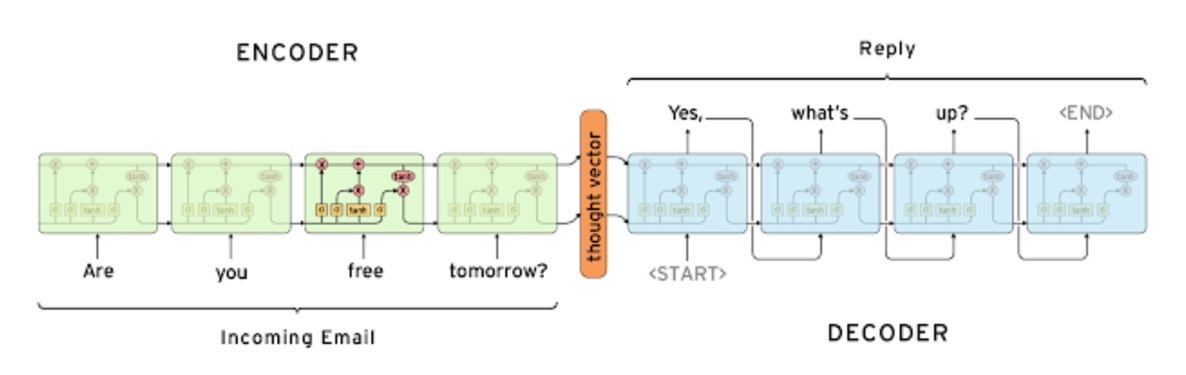
1) Encoder
Encoder에서는 Source sentence를 고정된 차원의 벡터로 만들어 Decoder에서 이를 처음 또는 매 time step마다 하나의 input으로 사용합니다. 이 벡터를 context vector라고 합니다.
2) Decoder
Decoder에서는 첫 hidden_state로는 Encoder에서 받아온 context vector를 사용합니다. 그리고 다음 time step부터는 Decoder의 hidden_state를 사용합니다. input은 Teacher forcing을 사용한다면 50% 확률로 이전 time step의 predicted token 또는 target token을 사용합니다. 참고로 context_vector를 처음에 한번만 hidden_state로 사용해야하는 것은 아닙니다. 원한다면 매 time_step마다 context_vector또한 하나의 입력으로 계속 사용할 수 있습니다. 또한 가장 처음 hidden_state에만 context vector가 사용되었다고 하더라도 저희의 모델은 recurrent하기 때문에, 그 값은 Decoder내에서 계속 값이 남아있다고 볼 수 있습니다.
3. 세부사항
- 인코더에 Bidirectional을 적용하였다
- 디코더에 <SoS>와 <EoS>를 사용하여 prediction을 시작하고 끝맺는다
- LSTM, Reversing Source sentences를 이용한 Long term dependency문제 해결했다
- Beam search
5. 코드
데이터 준비 관련 코드
import random
import torch
from torch import nn
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
vocab_size = 100
pad_id = 0
sos_id = 1
eos_id = 2
src_data = [
[3, 77, 56, 26, 3, 55, 12, 36, 31],
[58, 20, 65, 46, 26, 10, 76, 44],
[58, 17, 8],
[59],
[29, 3, 52, 74, 73, 51, 39, 75, 19],
[41, 55, 77, 21, 52, 92, 97, 69, 54, 14, 93],
[39, 47, 96, 68, 55, 16, 90, 45, 89, 84, 19, 22, 32, 99, 5],
[75, 34, 17, 3, 86, 88],
[63, 39, 5, 35, 67, 56, 68, 89, 55, 66],
[12, 40, 69, 39, 49]
]
trg_data = [
[75, 13, 22, 77, 89, 21, 13, 86, 95],
[79, 14, 91, 41, 32, 79, 88, 34, 8, 68, 32, 77, 58, 7, 9, 87],
[85, 8, 50, 30],
[47, 30],
[8, 85, 87, 77, 47, 21, 23, 98, 83, 4, 47, 97, 40, 43, 70, 8, 65, 71, 69, 88],
[32, 37, 31, 77, 38, 93, 45, 74, 47, 54, 31, 18],
[37, 14, 49, 24, 93, 37, 54, 51, 39, 84],
[16, 98, 68, 57, 55, 46, 66, 85, 18],
[20, 70, 14, 6, 58, 90, 30, 17, 91, 18, 90],
[37, 93, 98, 13, 45, 28, 89, 72, 70]
]
# trg_data에 <sos>, <eos> 토큰을 붙입니다 -> prediction을 언제 시작하고 멈출지 정하기 위해
trg_data = [[sos_id]+seq+[eos_id] for seq in tqdm(trg_data)]
# 더 쉬운 방법은 torch.nn.utils.rnn.pad_sequence(data)
# 근데 이 방법은 나중에 필요한 src_lens -> src_batch_lens를 못 구한다 (여기 함수 안에서는 valid_lens로 정의)
# valid_lens: 패딩하기 전 각 sequence의 길이
def padding(data, is_src=True):
max_len = len(max(data, key=len))
print(f"Maximum sequence length: {max_len}")
valid_lens = []
for i, seq in enumerate(tqdm(data)):
valid_lens.append(len(seq))
if len(seq) < max_len:
data[i] = seq + [pad_id] * (max_len - len(seq))
return data, valid_lens, max_len
# src_data와 trg_data를 패딩합니다 -> batch 단위로 학습하기 위해
# 근데 pack_padded_sequence에 input으로 넣어줄 예정 -> 패딩된 부분은 input으로 쓰지 않는 효율적인 연산 제공
src_data, src_lens, src_max_len = padding(src_data)
trg_data, trg_lens, trg_max_len = padding(trg_data)
# B: batch size, S_L: source maximum sequence length, T_L: target maximum sequence length
src_batch = torch.LongTensor(src_data) # (B, S_L)
src_batch_lens = torch.LongTensor(src_lens) # (B)
trg_batch = torch.LongTensor(trg_data) # (B, T_L)
trg_batch_lens = torch.LongTensor(trg_lens) # (B)
# PackedSquence를 사용을 위해 source data를 기준으로 정렬
# torch의 sort는 index의 이동도 추적한다
src_batch_lens, sorted_idx = src_batch_lens.sort(descending=True)
src_batch = src_batch[sorted_idx]
trg_batch = trg_batch[sorted_idx]
trg_batch_lens = trg_batch_lens[sorted_idx]
인코더와 디코더 코드
embedding_size = 256
hidden_size = 512
num_layers = 2
num_dirs = 2
dropout = 0.1
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.gru = nn.GRU(
input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=True if num_dirs > 1 else False,
dropout=dropout
)
self.linear = nn.Linear(num_dirs * hidden_size, hidden_size)
def forward(self, batch, batch_lens): # batch: (B, S_L), batch_lens: (B)
# d_w: (word) embedding size
batch_emb = self.embedding(batch) # (B, S_L, d_w)
batch_emb = batch_emb.transpose(0, 1) # (S_L, B, d_w) # batch first=True 하면 편할텐데..
packed_input = pack_padded_sequence(batch_emb, batch_lens) # PackedSequence 객체 리턴
h_0 = torch.zeros((num_layers * num_dirs, batch.shape[0], hidden_size)) # (num_layers*num_dirs, B, d_h) = (4, B, d_h)
packed_outputs, h_n = self.gru(packed_input, h_0) # h_n: (4, B, d_h)
outputs = pad_packed_sequence(packed_outputs)[0] # outputs: (S_L, B, 2d_h)
forward_hidden = h_n[-2, :, :]
backward_hidden = h_n[-1, :, :]
hidden = self.linear(torch.cat((forward_hidden, backward_hidden), dim=-1)).unsqueeze(0) # (1, B, d_h)
return outputs, hidden
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size)
self.gru = nn.GRU(
input_size=embedding_size,
hidden_size=hidden_size,
)
self.output_layer = nn.Linear(hidden_size, vocab_size)
# Decoder의 input인 batch는 매번 한 time_step 밖에 안들어옴 -> 그래서 뒤에 Seq2seq모델에서 for문 돌림
# 이렇게 하는 이유는 매 time_step마다 context vector가 사용되도록 하기 위해
# 근데 이러면 Decoder 내의 hidden_state는 사용이 안되는데...?
def forward(self, batch, hidden): # batch: (B), hidden: (1, B, d_h)
batch_emb = self.embedding(batch) # (B, d_w)
batch_emb = batch_emb.unsqueeze(0) # (1, B, d_w)
outputs, hidden = self.gru(batch_emb, hidden) # outputs: (1, B, d_h), hidden: (1, B, d_h)
# V: vocab size
outputs = self.output_layer(outputs) # (1, B, V)
return outputs.squeeze(0), hidden
Seq2Seq모델 코드
class Seq2seq(nn.Module):
def __init__(self, encoder, decoder):
super(Seq2seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, src_batch, src_batch_lens, trg_batch, teacher_forcing_prob=0.5):
# src_batch: (B, S_L), src_batch_lens: (B), trg_batch: (B, T_L)
_, hidden = self.encoder(src_batch, src_batch_lens) # hidden: (1, B, d_h)
# <sos> 토큰
input_ids = trg_batch[:, 0] # (B)
batch_size = src_batch.shape[0]
outputs = torch.zeros(trg_max_len, batch_size, vocab_size) # (T_L, B, V)
# Decoder에서는 predict length가 정해진 것이 아니므로 for문을 이용한다
# 그래서 Decoder의 GRU에는 input의 seq_length가 1로 되어있다
for t in range(1, trg_max_len):
# 처음 hidden은 context vector 이 후의 hidden state는 Decoder내에서 만들어진 hidden
decoder_outputs, hidden = self.decoder(input_ids, hidden) # decoder_outputs: (B, V), hidden: (1, B, d_h)
outputs[t] = decoder_outputs
_, top_ids = torch.max(decoder_outputs, dim=-1) # top_ids: (B)
# input_ids는 실제 target의 t번째 token일 수도 있고 predict의 token일 수도 있다
input_ids = trg_batch[:, t] if random.random() > teacher_forcing_prob else top_ids
print(f"input_ids: {input_ids}")
return outputs
encoder = Encoder()
decoer = Decoder()
seq2seq = Seq2seq(encoder, decoder)
6. 참조
[1] N.Kalchbrenner and P.Blunsom, Recurent continuous translation models, In EMNLP, 2013