
KLUE를 이용한 문장 내 개체간 관계 추출 1주차
1. KLUE(Korean Language Understanding Evaluation)
- 목적: 한국어 자연어 이해 모델 평가를 위한 벤치마크
- 논문: KLUE: Korean Language Understanding Evaluation
- 데이터 셋: github
1) Intro
- AI가 사람의 언어를 얼마나 잘 이해하는지 평가하려면 여러 방면에서 평가되어야 함
- GLUE 벤치마크: 9개의 과제를 활용해 AI가 자연어(영어)이해 모델의 종합적인 성능 평가
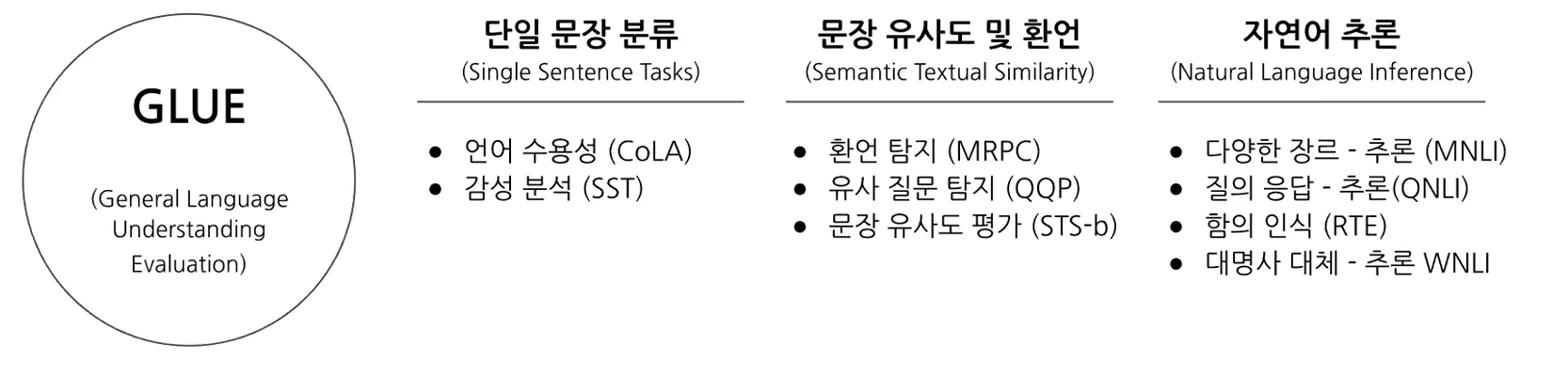
- 이 후 여러 가지 언어에 대한 유사한 벤치마크가 등장

- Upstage, NAVER, Kaist 등 여러 기관들이 한국어 벤치마크를 위해 공동으로 KLUE 프로젝트 제작
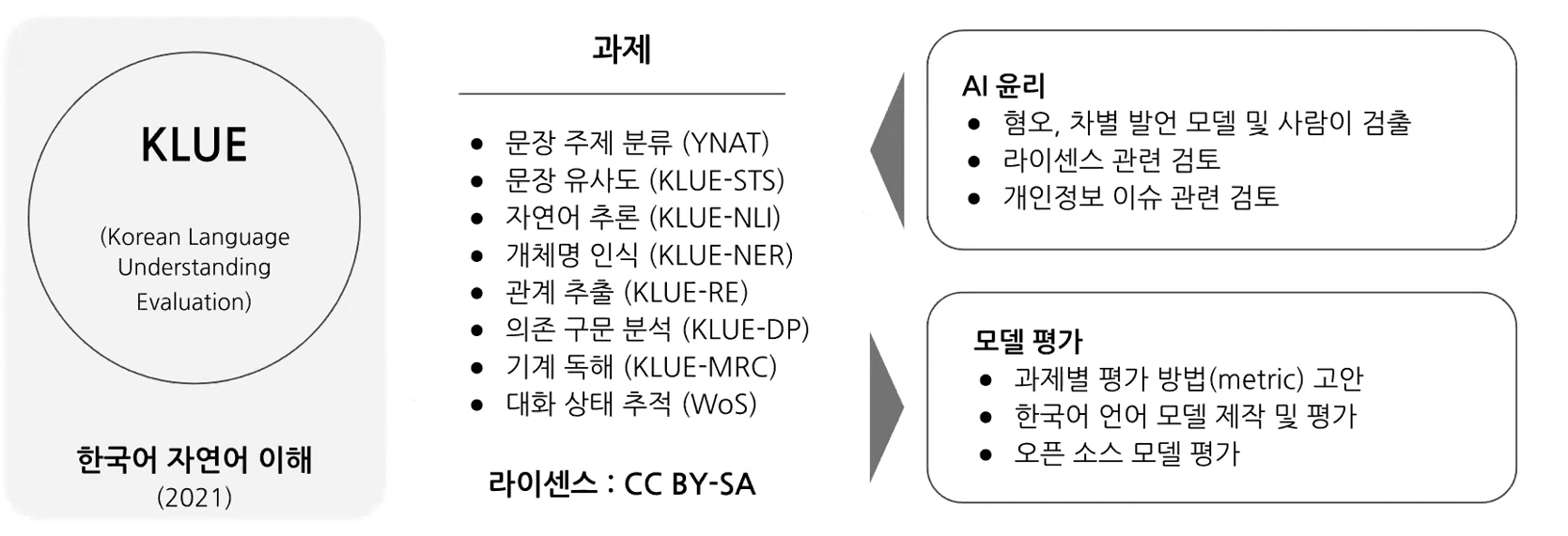
2) Source corpora
3) Tasks
- YNAT(Yonhap News Agency Topic): 주제 분류
- KLUE-STS(Semantic Textual Similarity): 문장 유사도 평가
- KLUE-NLI(Natural Language Inference): 자연어 추론
- KLUE-NER(Named Entity Recognition): 개체명 인식
- KLUE-RE(Relation Extraction): 관계 추론
- KLUE-DP(Dependency Parsing): 의존 구문 분석
- KLUE-MRC(Machine Reading Comprehension): 기계 독해
- WoS(Wizard-of-Seoul): 대화 상태 추적
4) Our competition: KLUE-RE
이번에 제가 진행할 대회는 위의 과제중 문장 내에서 관계를 추론하는 KLUE-RE task입니다. 문장 속에서 단어간에 관계성을 파악하는 것은 의미나 의도를 해석함에 있어서 많은 도움을 줍니다.
관계 추출(Relation Extraction)은 문장의 단어(Entity)에 대한 속성과 관계를 예측하는 문제입니다. 관계 추출은 지식 그래프 구축을 위한 핵심 구성 요소로, 구조화된 검색, 감정 분석, 질문 답변하기, 요약과 같은 자연어처리 응용 프로그램에서 중요합니다. 비구조적인 자연어 문장에서 구조적인 triple을 추출해 정보를 요약하고, 중요한 성분을 핵심적으로 파악할 수 있습니다.
이번 대회에서는 문장 속에서 단어 사이의 관계를 추론하는 모델을 학습시킵니다. 이를 통해 우리의 인공지능 모델이 단어들의 속성과 관계를 파악하며 개념을 학습할 수 있습니다. 우리의 model이 정말 언어를 잘 이해하고 있는 지, 평가해 보도록 합니다.
- 데이터 특징
- 학습을 위한 데이터: 32470개
- 테스트를 위한 데이터: 7765개
- Input: 문장과 두 Entity의 위치(start_idx, end_idx)
- Target: 카테고리 30개 중 1개
- Input/Target 예시

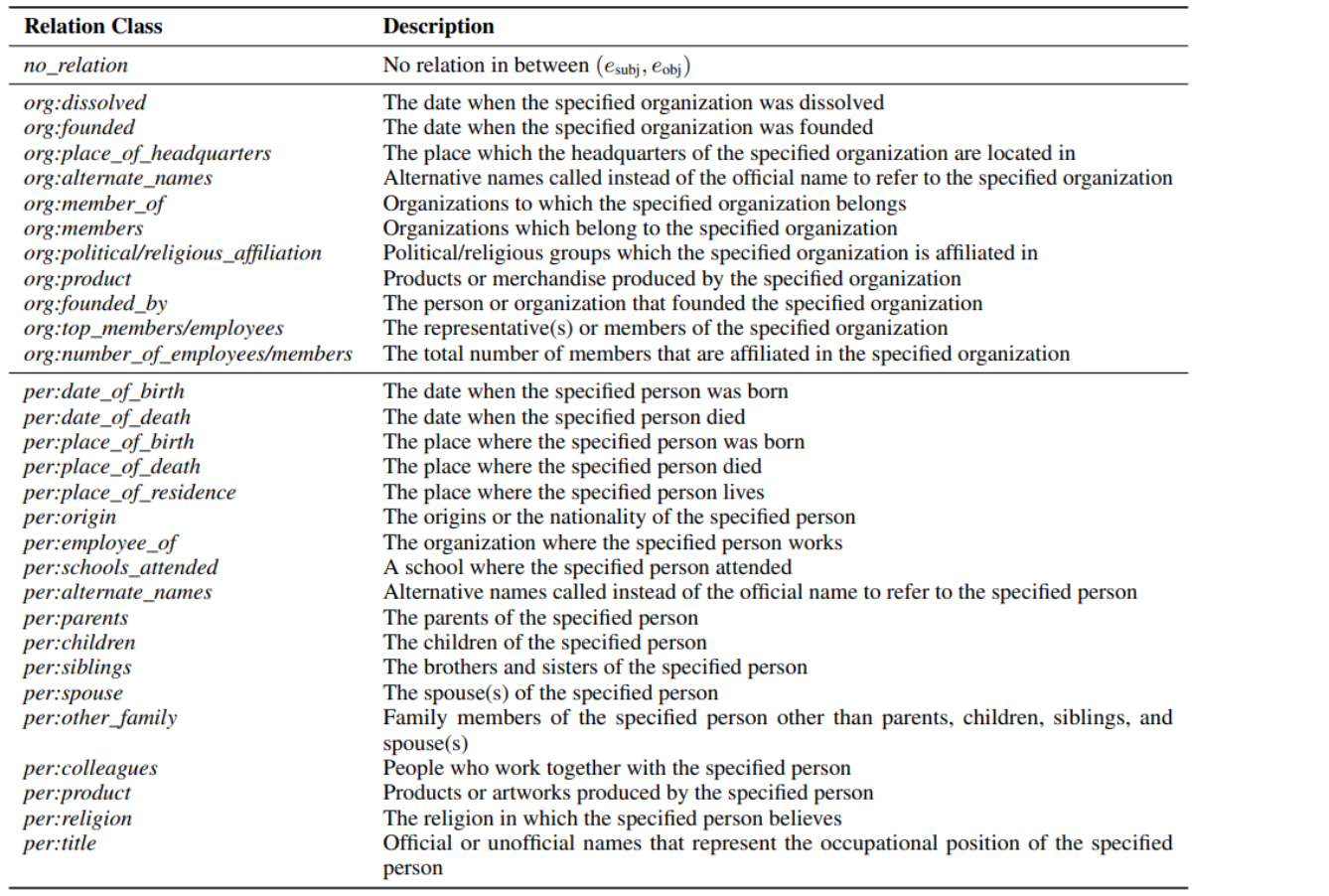
- 카테고리 종류
- 평가 방식
- Micro F1-Score: micro-precision과 micro-recall의 조화 평균이며, 각 샘플에 동일한 importance를 부여해, 샘플이 많은 클래스에 더 많은 가중치를 부여합니다. 데이터 분포상 많은 부분을 차지하고 있는 no_relation class는 제외하고 F1 score가 계산 됩니다.
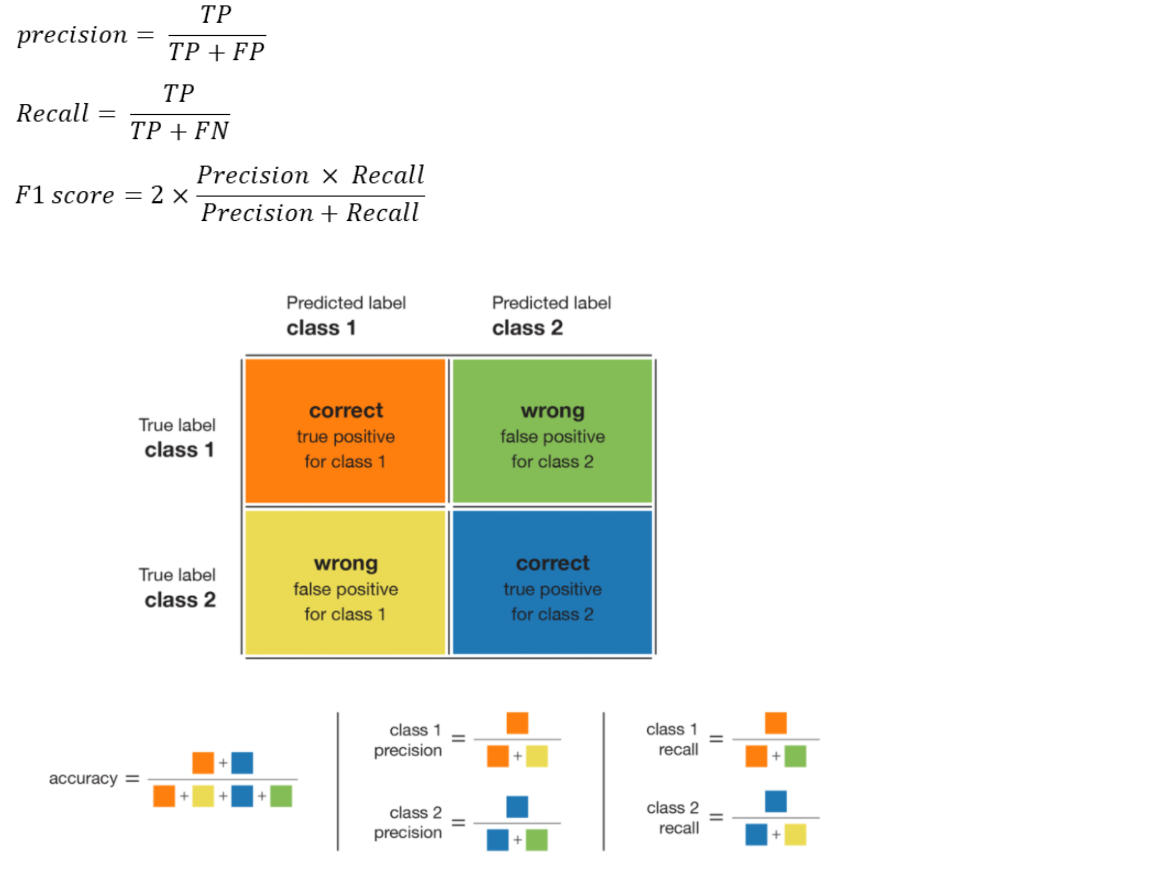
- AUPRCL: x축은 Recall, y축은 Precision이며, 모든 class에 대한 평균적인 AUPRC로 계산해 score를 측정 합니다. imbalance한 데이터에 유용한 metric 입니다.
2. Huggingface
HuggingFace는 매우 인기있는 Transformers 라이브러리를 구축하고 유지하는 회사입니다. 이 라이브러리를 통해 오늘날 사용 가능한 대부분의 크고 최첨단 transformer 모델을 사용하여 쉽게 시작할 수 있습니다.