
Embedding layer의 임베딩 벡터 학습을 통한 임베딩 벡터 만들기
파이토치에서는 임베딩 벡터를 사용하는 방법이 크게 두 가지가 있습니다. 바로 임베딩 층(embedding layer)을 만들어 훈련 데이터로부터 처음부터 임베딩 벡터를 학습하는 방법과 미리 사전에 훈련된 임베딩 벡터(pre-trained word embedding)들을 가져와 사용하는 방법입니다. 먼저 전자에 해당되는 방법에 대해서 배웁니다. 파이토치에서는 이를 nn.Embedding()를 사용하여 구현합니다.
임베딩 층의 입력으로 사용하기 위해서 입력 시퀀스의 각 단어들은 모두 정수 인코딩이 되어있어야 합니다.
임베딩 층은 입력 정수에 대해 밀집 벡터(dense vector)로 맵핑하고 이 밀집 벡터는 인공 신경망의 학습 과정에서 가중치가 학습되는 것과 같은 방식으로 훈련됩니다. 훈련 과정에서 단어는 모델이 풀고자하는 작업에 맞는 값으로 업데이트 됩니다. 그리고 이 밀집 벡터를 임베딩 벡터라고 부릅니다.
정수를 밀집 벡터 또는 임베딩 벡터로 맵핑한다는 것은 어떤 의미일까요? 특정 단어와 맵핑되는 정수를 인덱스로 가지는 테이블로부터 임베딩 벡터 값을 가져오는 룩업 테이블이라고 볼 수 있습니다. 그리고 이 테이블은 단어 집합의 크기만큼에 해당하는 행을 가지므로 모든 단어는 고유한 임베딩 벡터를 가집니다.
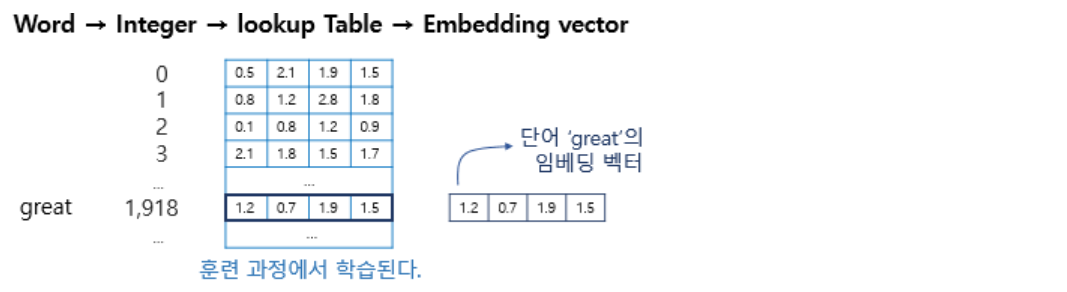
참고로 파이토치는 원-핫 벡터를 사용하는 것이 아니라, 단어를 정수 인덱스로만 바꾼채로 임베딩 층의 입력으로 사용해도 룩업 테이블 된 결과인 임베딩 벡터를 리턴합니다.
# 단어에 고유한 정수가 맵핑되어 있는 단어 집합 생성
train_data = 'you need to know how to code'
word_set = set(train_data.split()) # 중복을 제거한 단어들의 집합인 단어 집합 생성.
vocab = {token: i+2 for i, token in enumerate(word_set)}
vocab['<unk>'] = 0
vocab['<pad>'] = 1
print(vocab)
--------------------------------------------------------
{'you': 2,
'how': 3,
'code': 4,
'know': 5,
'need': 6,
'to': 7,
'<unk>': 0,
'<pad>': 1}
import torch.nn as nn
embedding_layer = nn.Embedding(num_embeddings = len(vocab),
embedding_dim = 3, # 임베딩 벡터를 3차원으로 할 것이다
padding_idx = 1) # 패딩할 토큰의 인덱스 값
print(embedding_layer.weight)
---------------------------------------------------------------
Parameter containing:
tensor([[-0.1778, -1.9974, -1.2478],
[ 0.0000, 0.0000, 0.0000],
[ 1.0921, 0.0416, -0.7896],
[ 0.0960, -0.6029, 0.3721],
[ 0.2780, -0.4300, -1.9770],
[ 0.0727, 0.5782, -3.2617],
[-0.0173, -0.7092, 0.9121],
[-0.4817, -1.1222, 2.2774]], requires_grad=True)
# 단어 you의 임베딩 벡터의 초기값
embedding_layer.weight[vocab['you']]
--------------------------------------------------
tensor([-0.5203, 0.4385, 1.3685], grad_fn=<SelectBackward>)
이제 embedding_layer를 학습시킴으로써 임베딩 벡터를 얻을 수 있다.
사전 훈련된 임베딩 벡터를 통한 임베딩 벡터 만들기
임베딩 벡터를 얻기 위해서 파이토치의 nn.Embedding()을 사용하기도 하지만, 때로는 이미 훈련되어져 있는 워드 임베딩을 불러서 이를 임베딩 벡터로 사용하기도 합니다. 훈련 데이터가 부족한 상황이라면 모델에 파이토치의 nn.Embedding()을 사용하는 것보다 다른 텍스트 데이터로 사전 훈련되어 있는 임베딩 벡터를 불러오는 것이 나은 선택일 수 있습니다.
이 경우, 해당 문제에 특화된 것은 아니지만 보다 일반적이고 보다 많은 훈련 데이터로 이미 Word2Vec이나 GloVe 등으로 학습되어져 있는 임베딩 벡터들을 사용하는 것이 성능의 개선을 가져올 수 있습니다.
from torchtext.vocab import GloVe, vocab
# 사전 훈련된 임베딩 벡터 룩업 테이블 다운 및 객체 생성 (파일 크기: 약 2GB)
# FastTEXT()같은 경우는 6GB 이상
myvec = GloVe(name='840B', dim=300)
# 단어와 인덱스가 맵핑되어 있는 단어사전 생성
myvoca = vocab(myvec.stoi)
myvoca['apple']
------------------
4977
myvoca['korea']
------------------
37565
myvec.vectors.shape
----------------------
torch.Size([2196017, 300])
# korea에 해당하는 임베딩 벡터
myvec.vectors[voca['korea']]
--------------------------------
tensor([ 1.1644, -0.2709, -0.3548, 0.1707, -0.0212, 0.0210, -0.0712, -0.0988,
0.2080, 1.1112, -0.0467, 0.2485, -0.2698, 0.3791, 0.2111, 0.2164,
0.3902, -0.7724, 0.0485, -0.2625, -0.3243, 0.0717, 0.7860, 0.1874,
-0.0043, -0.4715, -0.0938, 0.3439, -0.2612, 0.2997, 0.8434, -0.4661,
.................................................................
-0.2440, 0.1785, 0.1221, -0.1494, 0.2927, -0.0505, -0.1164, -0.0884,
0.5738, 0.6519, 0.1352, -0.0229, -0.0743, 0.6488, 0.0973, 0.0712,
0.2671, 0.1012, 0.1367, -0.1170, 0.7502, 0.0818, -0.1389, 0.1704,
-0.1074, 0.1779, -0.2292, -0.4394, -0.5149, 0.5386, 0.1338, -0.4358,
0.4550, 0.0660, 0.0543, 0.0654, 0.5629, -0.4468, -0.5002, -0.3005,
-0.4144, 0.6394, -0.2094, -0.1424])
# 임베딩 층으로 만들어 나의 코퍼스를 이용해 Fine-tuning
my_embeddings = torch.nn.Embedding.from_pretrained(myvec.vectors, freeze=True)