판다스
- R에서 데이터 보관, 분석에 용이한 DataFrame을 pandas가 파이썬에 그대로 가져왔다.
- numpy와 달리 다른 자료형의 데이터를 같이 저장할 수 있다.
- 2차원 데이터를 효율적으로 가공/처리할 수 있는 라이브러리다.
1. 판다스의 주요 구성 요소

- DataFrame: column과 row로 이루어진 2차원 데이터 셋
- Series: 1개의 column으로 이루어진 1차원 데이터 셋
2. 테이블(DataFrame, Series) 만들기
판다스에서 테이블을 만들 때, 여러 종류의 데이터를 이용할 수 있습니다. 이들을 DataFrame과 Series 타입의 데이터로 만드는 방법을 알아보겠습니다.
DataFrame 테이블은 pd.DataFrame()를 사용하여 생성합니다. 다음의 공식 문서를 보며 어떤 값들을 인자로 받는지 살펴보겠습니다.
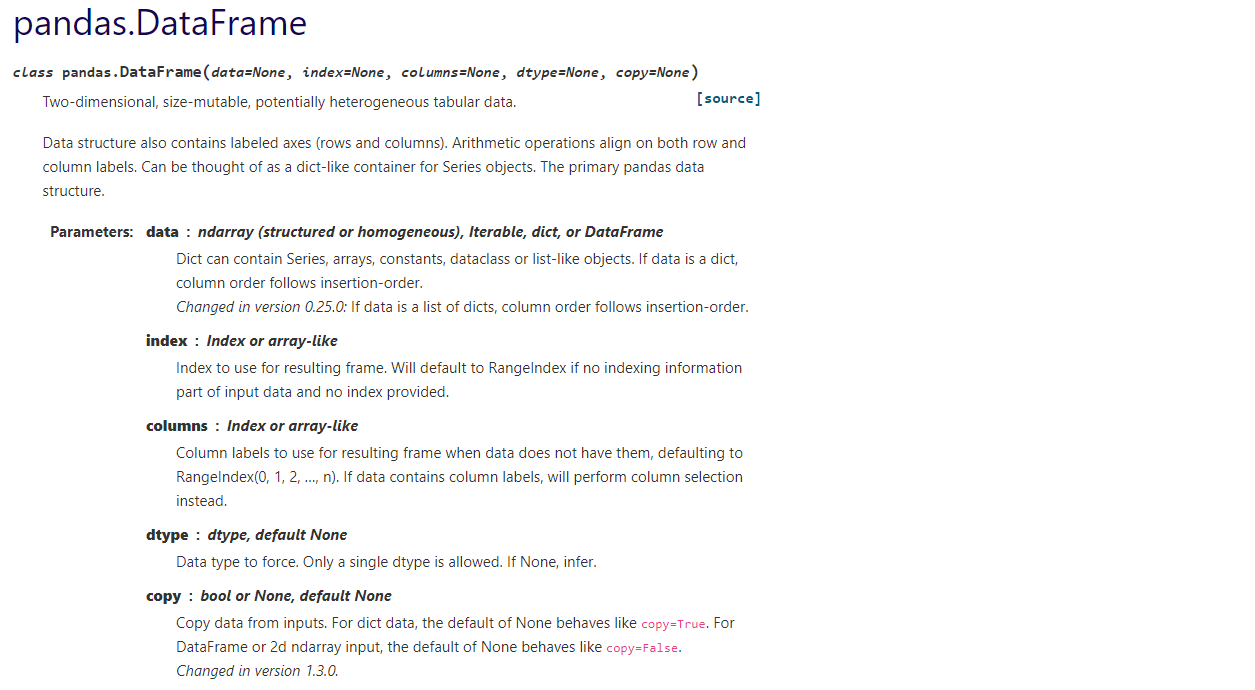
모든 인자의 default값이 None으로 되어있는 것으로 봐서 아무런 값도 주지 않으면 빈 DataFrame이 생성되는 것 같습니다. 인자를 하나씩 살펴보면 data는 저희가 사용할 데이터를 의미합니다. 사용할 수 있는 타입은 Iterable객체(List, Tuple, Dict, Series 등) 또는 DataFrame입니다. index, columns은 말 그대로 각각 index와 column명을 나타내고 List정도를 넣으면 될 것 같습니다. 지정해주지 않으면 RangeIndex(0, 1, …, n)가 사용됩니다. dtype은 강제하고 싶은 데이터의 타입을 지정할 수 있도록 합니다. 예시를 몇 가지 보도록 하겠습니다.
1) 리스트로 만들기
df = pd.DataFrame([['Steven Gerrard','England', 'Liverpool'],
['Paul Labile Pogba','France','Manchester United'],
['Zinedine Zidane','France','Real Madrid'],
['Zlatan Ibrahimović','Sweden','Juventus'],
['Cristiano Ronaldo','Portugal','Manchester United'],
['Patrick Vieira','France','Arsenal']])
df
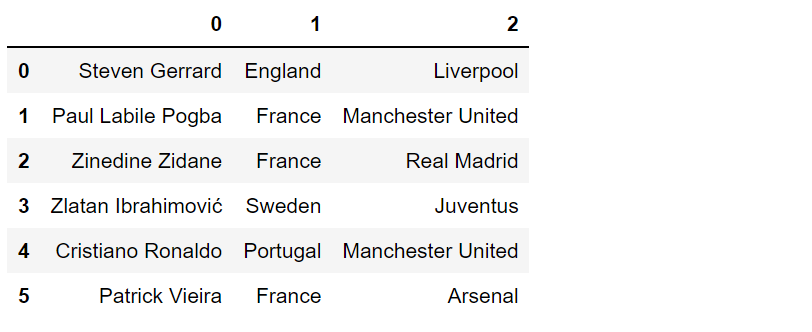
columns인자를 추가해 보도록 하겠습니다.
df = pd.DataFrame([['Steven Gerrard','England', 'Liverpool'],
['Paul Labile Pogba','France','Manchester United'],
['Zinedine Zidane','France','Real Madrid'],
['Zlatan Ibrahimović','Sweden','Juventus'],
['Cristiano Ronaldo','Portugal','Manchester United'],
['Patrick Vieira','France','Arsenal']],
columns=['Name','Country','Team'])
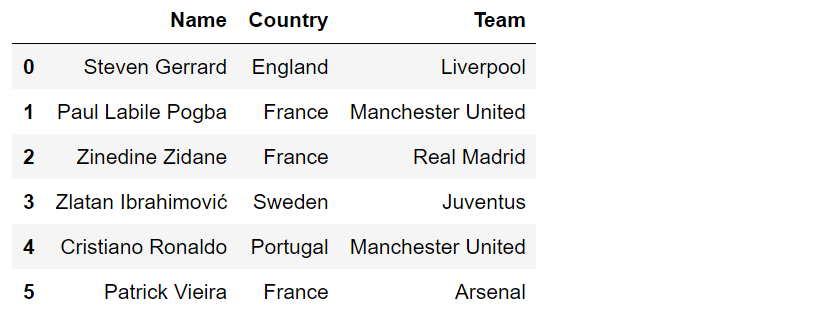
이번에는 index인자를 추가해 보겠습니다.
df = pd.DataFrame([['Steven Gerrard','England', 'Liverpool'],
['Paul Labile Pogba','France','Manchester United'],
['Zinedine Zidane','France','Real Madrid'],
['Zlatan Ibrahimović','Sweden','Juventus'],
['Cristiano Ronaldo','Portugal','Manchester United'],
['Patrick Vieira','France','Arsenal']],
columns=['Name','Country','Team'],
index=['no.1', 'no.2', 'no.3', 'no.4', 'no.5', 'no.6'])
df
2) Numpy의 Array로 만들기
ndarray 데이터 타입은 리스트랑 만드는 방법이 똑같습니다. 예시만 하나 보도록 하겠습니다.
array = np.array([['Steven Gerrard','England', 'Liverpool'],
['Paul Labile Pogba','France','Manchester United'],
['Zinedine Zidane','France','Real Madrid'],
['Zlatan Ibrahimović','Sweden','Juventus'],
['Cristiano Ronaldo','Portugal','Manchester United'],
['Patrick Vieira','France','Arsenal']])
df = pd.DataFrame(array)
3) List of Series로 만들기
Series 객체를 리스트로 묶은 형태 또한 DataFrame의 데이터로 사용할 수 있습니다. 이것도 예시만 하나 보도록 하겠습니다.
df = pd.DataFrame([pd.Series(['Steven Gerrard','England', 'Liverpool']),
pd.Series(['Paul Labile Pogba','France','Manchester United']),
pd.Series(['Zinedine Zidane','France','Real Madrid']),
pd.Series(['Zlatan Ibrahimović','Sweden','Juventus']),
pd.Series(['Cristiano Ronaldo','Portugal','Manchester United']),
pd.Series(['Patrick Vieira','France','Arsenal'])],
)
4) Dict로 만들기
앞에서는 그동안 row를 하나씩 만들어내는 방법이었습니다. 하지만 Dict로 만들 때는 row-order가 아니라 column-order입니다. 예시를 보도록 하겠습니다.
col_1 = ['Steven Gerrard','Paul Labile Pogba','Zinedine Zidane','Zlatan Ibrahimović','Cristiano Ronaldo','Patrick Vieira']
col_2 = ['England','France','France','Sweden','Portugal','France']
col_3 = ['Liverpool','Manchester United','Real Madrid','Juventus','Manchester United','Arsenal']
col_4 = ['no.1', 'no.2', 'no.3', 'no.4', 'no.5', 'no.6']
dic = {'Name': col_1, 'Country': col_2, 'Team': col_3}
df = pd.DataFrame(dic, index=col_4)
5) 외부 데이터 불러와서 만들기
사실상 실제로 데이터를 다루고 분석할 경우에는 위의 과정과 같이 직접 데이터를 만드는 경우는 잘 없습니다. 그보다는 외부에서 제공받은 데이터를 포맷에 맞게 불러와서 DataFrame으로 바꾸는 경우가 훨씬 흔합니다. 여기서는 그 중에서도 가장 자주 사용되는 read_csv를 사용해 보겠습니다.

read_csv에는 인자가 정말 많습니다. 이번 포스트에서는 필수적인 인자만 사용해보도록 하겠습니다.
# pd.read.csv(filepath_or_buffer='파일경로/파일명')
df = pd.read_csv('titanic_train.csv')
이상으로 DataFrame을 만드는 방법에 대해 살펴보았습니다. Series는 DataFrame과 거의 똑같으며 들어가는 data가 2차원이 아닌 1차원 배열이라는 점만 다릅니다.
3. 원래 데이터 얻기
DataFrame 형태의 데이터에서 다시 List, Numpy, Dict와 같은 데이터를 얻는 방법을 살펴보고 이번 포스트를 마치도록 하겠습니다.
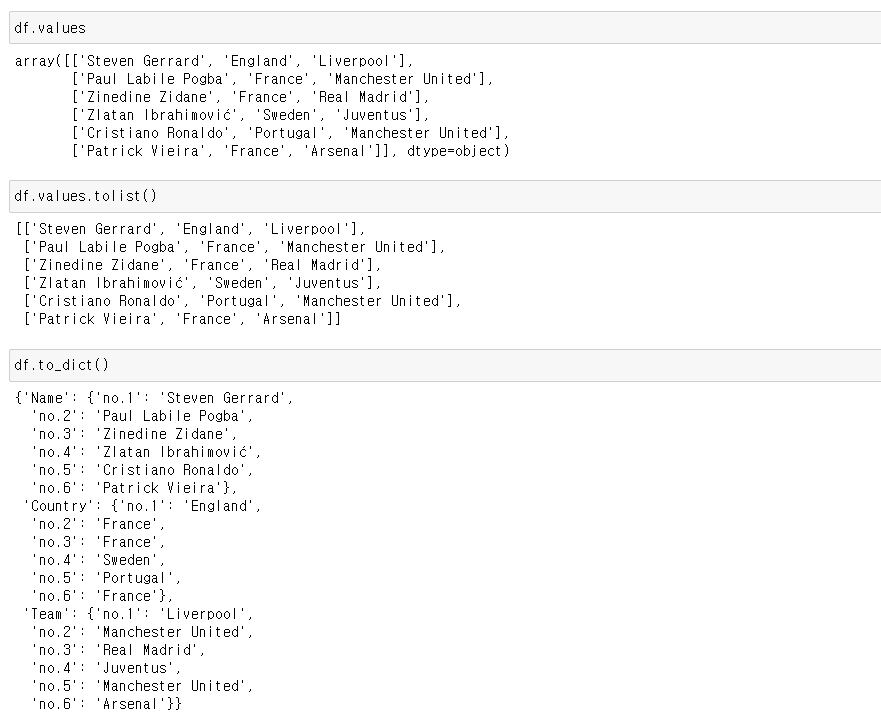
# DataFrame -> ndarray
df.values
# DataFrame -> (ndarray) -> list: ndarray로 중간 과정 거쳐야 한다
df.values.tolist()
# DataFrame -> dict
df.to_dict()