
1. Subword segmentation
단어보다 더 작은 의미 단위로 분절하는 것을 서브워드 분절이라고 합니다. 예를 들어 ‘집중’ 이라는 단어를 ‘집(모을 집)’, ‘중(가운데 중)’으로 나눌 수 있고, 영어의 경우 ‘Concentrate’를 ‘Con’, ‘centr’, ‘ate’로 나눌 수 있습니다. 근데 이렇게 굳이 나누는 이유가 뭘까요?
첫 번째로, 예를 들어 ‘집적’ 이라는 단어와 ‘중학교’ 라는 단어는 있는데 ‘집중’이라는 단어는 학습한 적이 없다고 해봅시다. 이런 경우 ‘집중’ 이라는 단어를 Oov(Out of vocabulary)라고 하며 Oov는 학습에 치명적인 악영향을 끼칩니다. 따라서 이러한 상황을 방지하고자, ‘집중’이라는 단어를 ‘집’, ‘중’ 으로 나누어 주는 것이 좋습니다.
두 번째로, 언어별 특성에 대해 크게 고민할 필요없이 segmentation을 할 수 있다는 것입니다.
하지만 모든 단어를 무조건 이런식으로 나누게 되면 데이터 별 시퀀스의 길이가 굉장히 길어지게 되고, 이는 모델을 만들 때 부담을 줄 수 있습니다.
ex) ‘학교에 간다’ -> [‘학교’, ‘에’, ‘간다’] vs [‘학’, ‘교’, ‘에’, ‘간’, ‘다’]
2. BPE(Byte Pair Encoding) 알고리즘
BPE 알고리즘은 같이 붙어서 등장하는 빈도수가 굉장히 높은 단어들은 하나로 만들어 주는 subword segmentation 기법입니다.
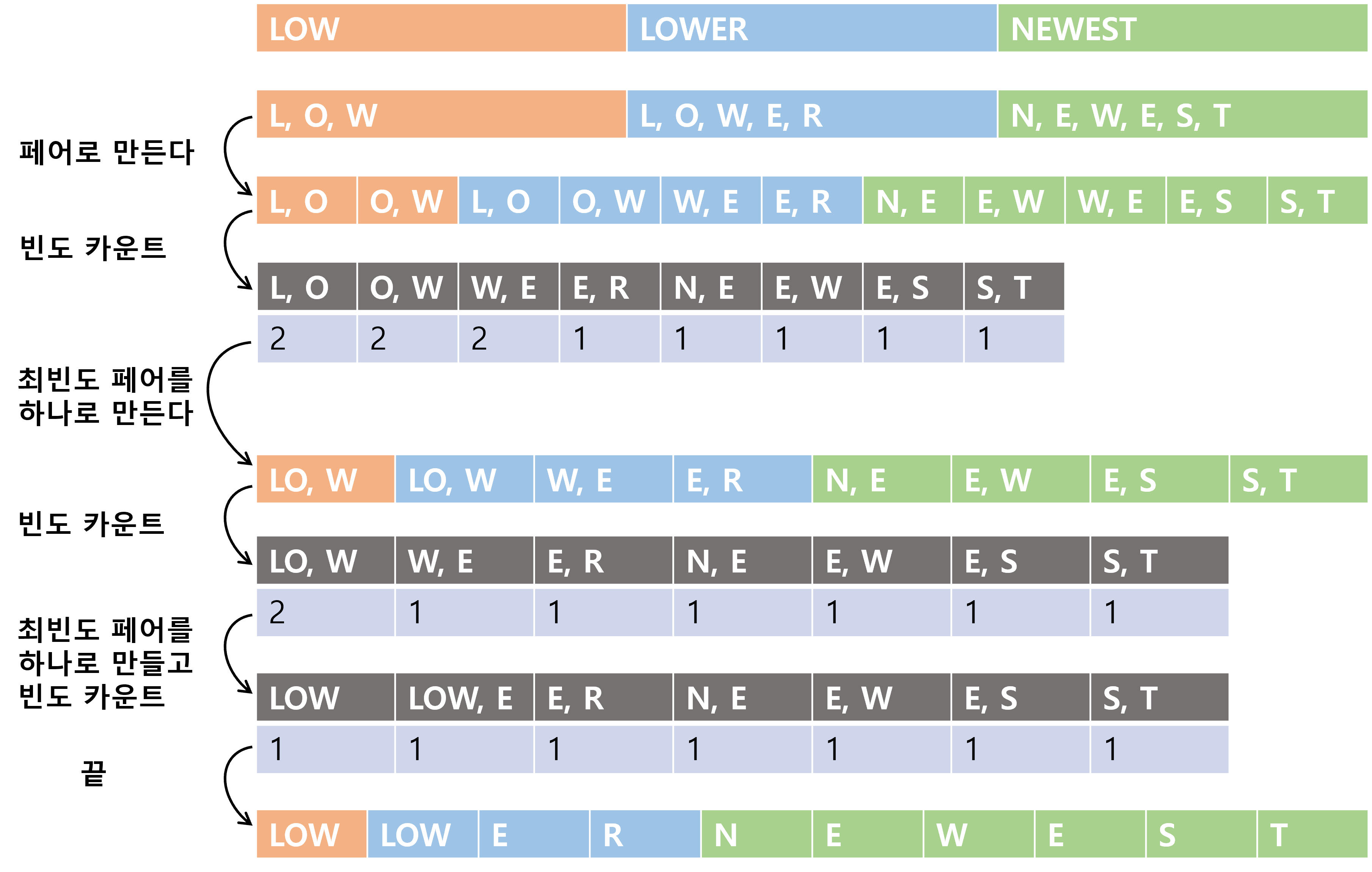
3. 인덱스 매핑
보통 여기까지 진행하고 나면 충분한 tokenization이 이루어졌다고 생각하고 단어를 인덱스로 매핑을하게 됩니다.