
카운트 기반
단어의 빈도수를 카운트(Count)하여 단어를 수치화하는 단어 표현 방법입니다. 이는 딥러닝 이전의 단어 임베딩 방법 중 하나로, 이 챕터에서는 BoW와 그의 확장인 DTM(또는 TDM)에 대해서 학습하고, 이러한 빈도수 기반 단어 표현에 단어의 중요도에 따른 가중치를 줄 수 있는 TF-IDF에 대해서 학습합니다.
BoW (Back of Words)
Bag of Words란 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법입니다. Bag of Words를 직역하면 단어들의 가방이라는 의미입니다. 단어들이 들어있는 가방을 상상해봅시다. 갖고있는 어떤 텍스트 문서에 있는 단어들을 가방에다가 전부 넣습니다. 그러고나서 이 가방을 흔들어 단어들을 섞습니다. 만약, 해당 문서 내에서 특정 단어가 N번 등장했다면, 이 가방에는 그 특정 단어가 N개 있게됩니다. 또한 가방을 흔들어서 단어를 섞었기 때문에 더 이상 단어의 순서는 중요하지 않습니다.
정부가 발표하는 물가상승률과 소비자가 느끼는 물가상승률은 다르다.
(‘정부’: 0, ‘가’: 1, ‘발표’: 2, ‘하는’: 3, ‘물가상승률’: 4, ‘과’: 5, ‘소비자’: 6, ‘느끼는’: 7, ‘은’: 8, ‘다르다’: 9)
[1, 2, 1, 1, 2, 1, 1, 1, 1, 1]
사이킷런에서는 단어의 빈도를 Count하여 Vector로 만드는 CountVectorizer 클래스를 지원합니다. 이를 이용하면 영어에 대해서는 손쉽게 BoW를 만들 수 있습니다.
동시 출현 행렬
특정 문맥 안에서 단어들이 동시에 등장하는 횟수를 직접세어 동시 출현 행렬을 만들고, 이 행렬을 수치화(SVD, LSA, Hellinger PCA 등)해서 단어 벡터로 만드는 방법 같은 방법을 통해 벡터화합니다.
TF-IDF (Term Frequency-Inverse Document Frequency)
TF-IDF는 단순히 횟수만을 특징으로 잡음으로써 생길 수 있는 단점(조사 혹은 지시대명사가 높은 특징값을 가지는 문제)을 해결해주는 카운트 기반의 단어 벡터화 방법입니다. 여기서 TF란 특정 단어가 하나의 데이터 안에서 등장하는 횟수를 의미하며, DF는 특정 단어가 등장하는 데이터의 수를 의미합니다. TF-IDF란 TF와 DF의 곱으로 어떤 단어가 해당 문서에는 자주 등장하지만 다른 문서에는 많이 없는 단어일수록 높은 값을 가지게 됩니다. 다음 데이터를 이용해 예를 들어보겠습니다.
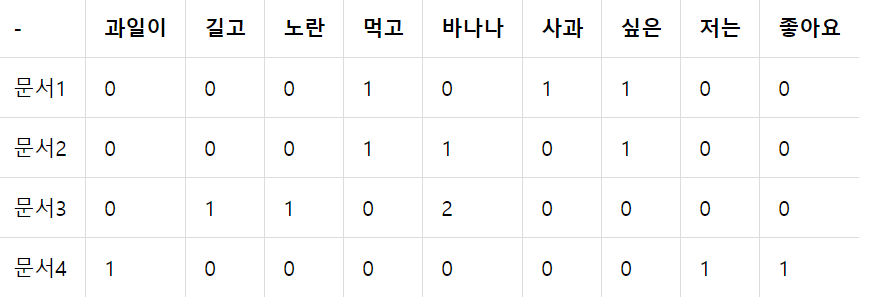
TF는 데이터 안에서 등장하는 횟수를 의미하므로 등장한 적 없으면 0, 한 번 등장하면 1이므로 위의 표 그대로 사용할 수 있습니다. IDF의 경우에는 주의할 점이 있습니다. 바로 단순히 역수가 아닌 IDF = log(데이터 수/(1+DF))라는 것입니다. log를 사용하지 않고, IDF를 DF의 역수(데이터 수/(1+DF))라는 식)로 사용한다면 총 문서의 수 n이 커질 수록, IDF의 값은 기하급수적으로 커지게 됩니다. 그렇기 때문에 log를 사용합니다. (보통 밑은 자연상수e를 사용하므로 ln이라고 생각해도 됩니다.)

TF-IDF의 결과는 다음과 같습니다.
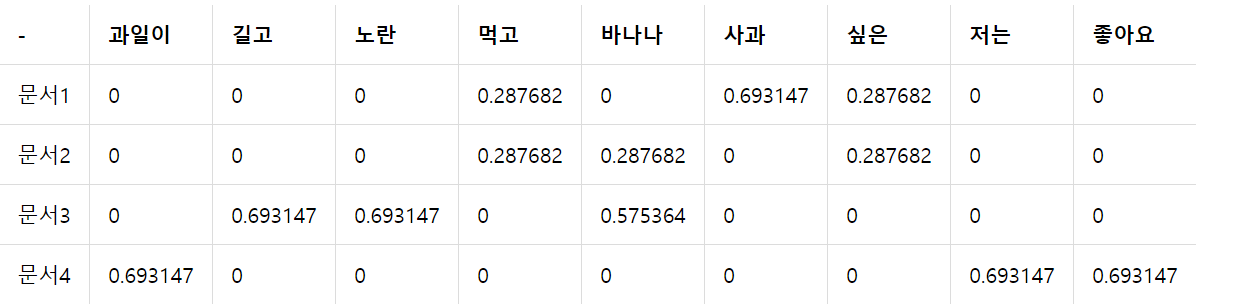
이 결과를 분석해보면 (길고, 노란), (과일이, 저는, 좋아요), (먹고, 싶은)이 서로 유사도가 높은 단어들이며, 그 단어들이 갖는 값을 통해 단어들의 중요도 또한 확인할 수 있습니다. 사실 이러한 결과는 데이터가 너무 적어서 유의미한 결과를 추출했다고 보기는 어렵지만 데이터가 충분히 많다면 이러한 분석이 도움이 될 것 입니다.