
FastText: Upgrade version of Skip-gram
빈도수가 낮은 단어 학습시 발생하는 문제를 해결하기 위해 만들어진 방법입니다.
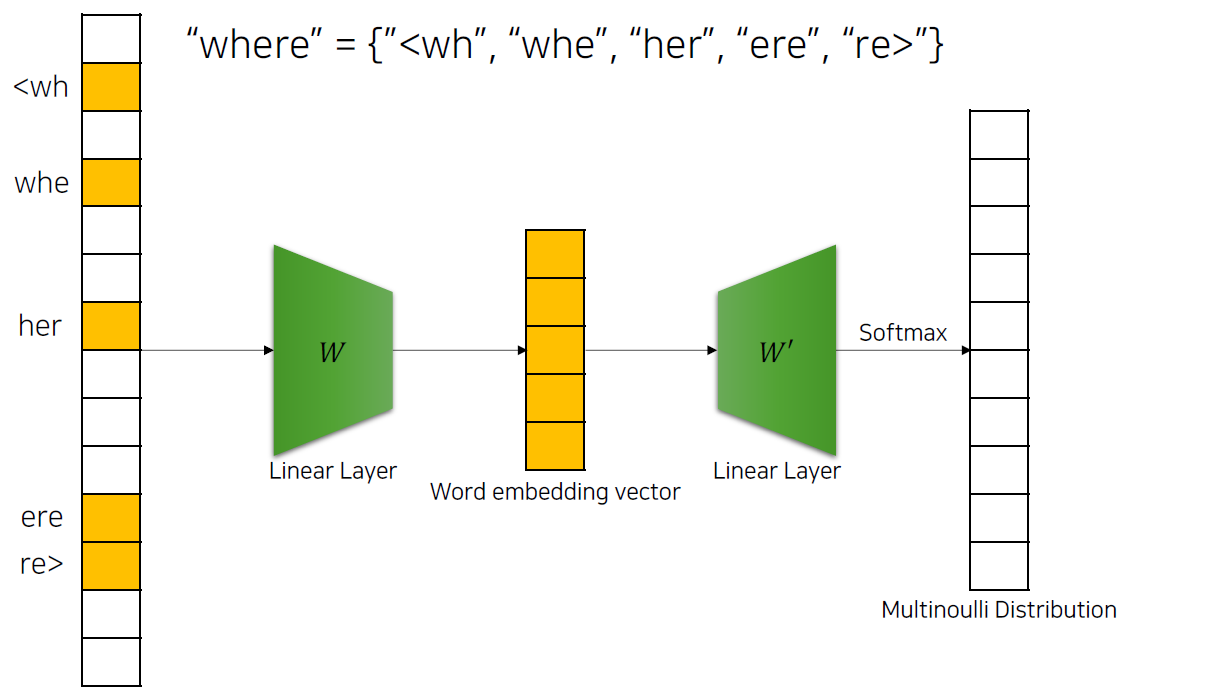
단어를 subword로 나누게 되면, 그 subword들은 더 이상 빈도수가 낮은 subword가 아니게 될 수 있고, 이를 바탕으로 Skip-gram을 활용하여, 각 subword에 대한 임베딩 벡터를 구하고, 최종적으로 이 subword들의 임베딩 벡터의 합이 word 임베딩 벡터가 됩니다.
강점: 모르는 단어(Out Of Vocabulary, OOV)에 대한 대응
FastText의 인공 신경망을 학습한 후에는 데이터 셋의 모든 단어의 각 n-gram에 대해서 워드 임베딩이 됩니다. 이렇게 되면 장점은 데이터 셋만 충분한다면 위와 같은 내부 단어(Subword)를 통해 모르는 단어(Out Of Vocabulary, OOV)에 대해서도 다른 단어와의 유사도를 계산할 수 있다는 점입니다.
가령, FastText에서 birthplace(출생지)란 단어를 학습하지 않은 상태라고 해봅시다. 하지만 다른 단어에서 birth와 place라는 내부 단어가 있었다면, FastText는 birthplace의 벡터를 얻을 수 있습니다. 이는 모르는 단어에 제대로 대처할 수 없는 Word2Vec, GloVe와는 다른 점입니다.
강점: 빈도 수가 적은 단어(Rare Word)에 대한 대응
Word2Vec의 경우에는 등장 빈도 수가 적은 단어(rare word)에 대해서는 임베딩의 정확도가 높지 않다는 단점이 있었습니다. 참고할 수 있는 경우의 수가 적다보니 정확하게 임베딩이 되지 않는 경우입니다.
하지만 FastText의 경우, 만약 단어가 희귀 단어라도, 그 단어의 n-gram이 다른 단어의 n-gram과 겹치는 경우라면, Word2Vec과 비교하여 비교적 높은 임베딩 벡터값을 얻습니다.
FastText가 노이즈가 많은 코퍼스에서 강점을 가진 것 또한 이와 같은 이유입니다. 모든 훈련 코퍼스에 오타(Typo)나 맞춤법이 틀린 단어가 없으면 이상적이겠지만, 실제 많은 비정형 데이터에는 오타가 섞여있습니다. 그리고 오타가 섞인 단어는 당연히 등장 빈도수가 매우 적으므로 일종의 희귀 단어가 됩니다. 즉, Word2Vec에서는 오타가 섞인 단어는 임베딩이 제대로 되지 않지만 FastText는 이에 대해서도 일정 수준의 성능을 보입니다.
예를 들어 단어 apple과 오타로 p를 한 번 더 입력한 appple의 경우에는 실제로 많은 개수의 동일한 n-gram을 가질 것입니다.
라이브러리
from gensim.models import FastText
# result는 전처리된 코퍼스
model = FastText(result, size=100, window=5, min_count=5, workers=4, sg=1)
# electrofishing과 유사한 단어
model.wv.most_similar("electrofishing")
-----------------------------------------------------------
[('electrolux', 0.7934642434120178), ('electrolyte', 0.78279709815979), ('electro', 0.779127836227417), ('electric', 0.7753111720085144), ('airbus', 0.7648627758026123), ('fukushima', 0.7612422704696655), ('electrochemical', 0.7611693143844604), ('gastric', 0.7483425140380859), ('electroshock', 0.7477173805236816), ('overfishing', 0.7435552477836609)]